
前言
从2012年 AlexNet发展至今,大牛们提出了各种CNN模型,目的就是增加准确率、更轻量。研究讨论这些模型的目的,也是为了分析一下日后CNN变革的方向
Group convolution
group convolution最早是在AlexNet中出现,由于当时的硬件资源有限,训练AlexNet时卷积操作不能同时全部放在同一个GPU处理。因此作者把feature maps分给多个GPU分别进行处理,最后把多个GPU的结果进行融合。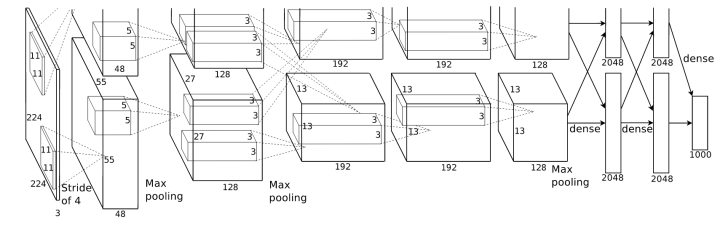
可以看到该图是分为上下两部分的。分别对应两张GPU中的处理。
但分组卷积至今仍有影响,一些轻量级的网络都有采用group convolution.
我们假设上一层的输出feature map有N个,即通道数channel=N,也就是说上一层有N个卷积核。再假设分组卷积的group数目为M。那么该分组卷积层的操作就是,先将channel 分成M份。每个group对应N/M个channel,与之独立连接。然后各个group卷积完成后输出叠在一起(concatenate),作为这一层的输出channel.
下面两张图可以很清楚地看到group convolution的作用
这是一个一般的没有分组的卷积层结构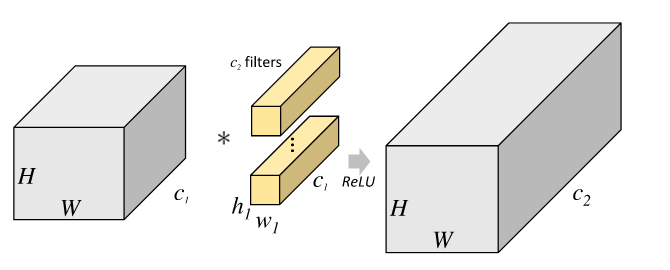
下图是分组卷积的结构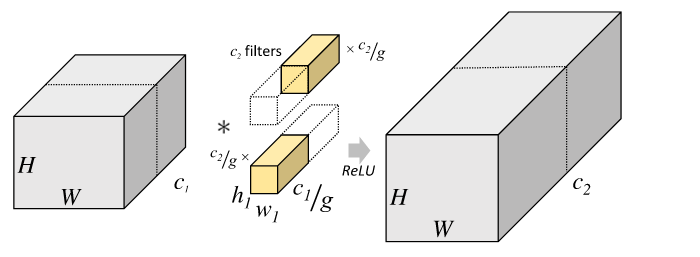
由此可见参数量大大减少了。
在pytorch中nn.Conv2d()是Pytorch中的卷积模块,里面有groups参数。groups表示输出数据体深度上和输入数据体深度上的联系,默认=1,也就是所有的输出和输入都是相关联的,如果=2,这表示输入的深度被分割成两份,输出的深度也被分成了两份,它们之间分别对应,所以要求输出和输入都必须被groups整除。
3×3的卷积核
AlexNet中用到了一些非常大的卷积核,比如11×11、5×5卷积核,之前人们的观念是,卷积核越大,receptive field(感受野)越大,看到的图片信息越多,因此获得的特征越好。虽说如此,但是大的卷积核会导致计算量的暴增,不利于模型深度的增加,计算性能也会降低。但是在VGG中,发现用2个3×3卷积核的组合比1个5×5卷积核的效果更佳,同时参数量被降低,之后3×3的卷积被广泛应用于了各个模型中。
inception结构
之前的各种网络都是,层叠式的网络,基本上都是一个个卷积层堆叠成的,每一层只用一个尺寸的卷积核,例如VGG结构中使用了大量的3×3的卷积层。Googlenet提出了inception的网络,可以对同一层feature map分别使用多个不同尺寸的卷积核以获得不同尺度的特征,再把这些特征结合起来,得到的特征往往比使用单一卷积核的要好。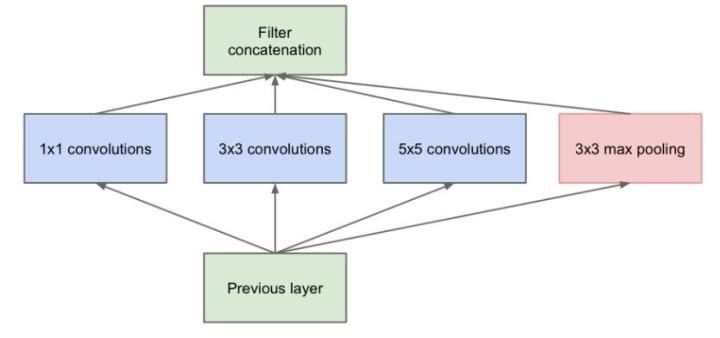
但这个结构有一个比较严重的问题:参数量比单个卷积核要多很多,如此庞大的计算量会使得模型效率低。
为了减少参数量,就提出了下述结构
Bottleneck
如果仅仅引入多尺寸得卷积核,会带来大量得额外得参数,受到Network in Network中的1×1卷积核的启发,来解决这里的问题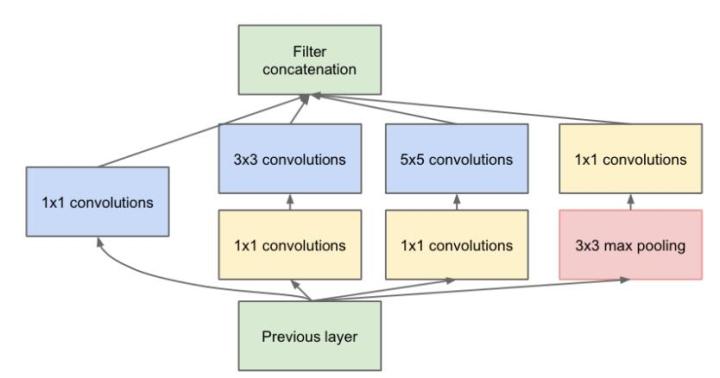
上图就是inception v2
为了更清晰地理解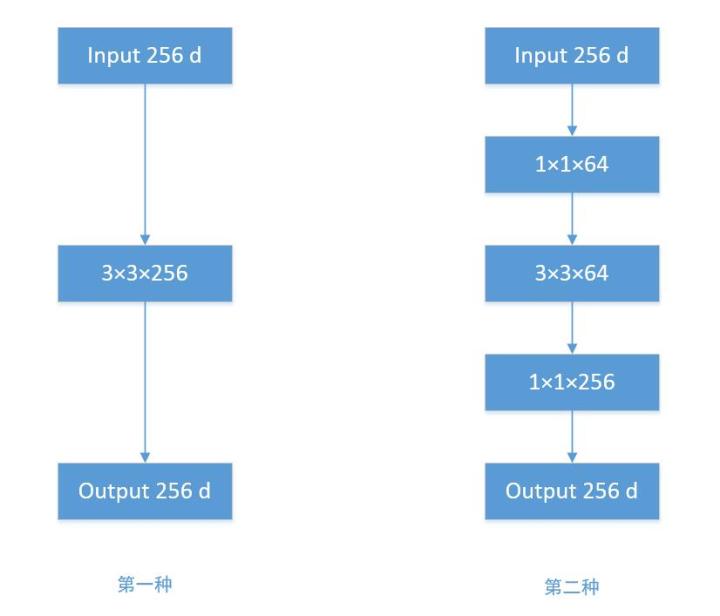
根据上图,我们来做个对比计算,假设输入feature map的维度为256维,要求输出维度也是256维。有以下两种操作:
- 256维的输入直接经过一个3×3×256的卷积层,输出一个256维的feature map,那么参数量为:256×3×3×256 = 589,824
- 256维的输入先经过一个1×1×64的卷积层,再经过一个3×3×64的卷积层,最后经过一个1×1×256的卷积层,输出256维,参数量为:256×1×1×64 + 64×3×3×64 + 64×1×1×256 = 69,632。足足把第一种操作的参数量降低到九分之一!
1×1卷积核也被认为是影响深远的操作,往后大型的网络为了降低参数量都会应用上1×1卷积核。
ResNet
随着网络的逐步加深,网络的表现会越来越差,主要是因为梯度弥散越来越验证。BP很难训练到较前面的层,为了解决这个问题就有了残差网络。引入了skip connection,带来的好处是对于较前面的层有一条捷径(short cut)使得它即使不能从它的后一层获得反向传播的梯度,但它可以通过捷径跳到更后面来获得。
DepthWise操作
从之前的模型我们可以看到卷积操作是对通道和区域同时考虑的。即一个卷积核在一个位置上卷积时,是同时对各个channel里的该位置同时进行卷积的。现在考虑把通道和空间区域分开考虑。
这是标准的卷积过程:一个区域上卷积同时用到所有channel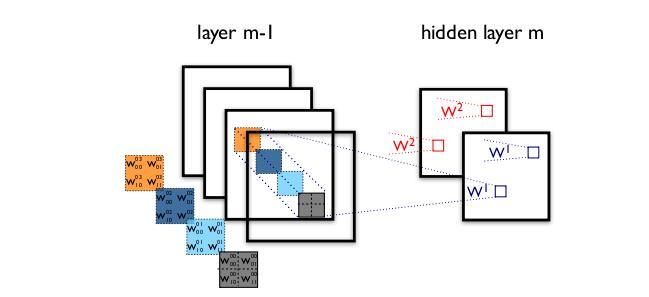
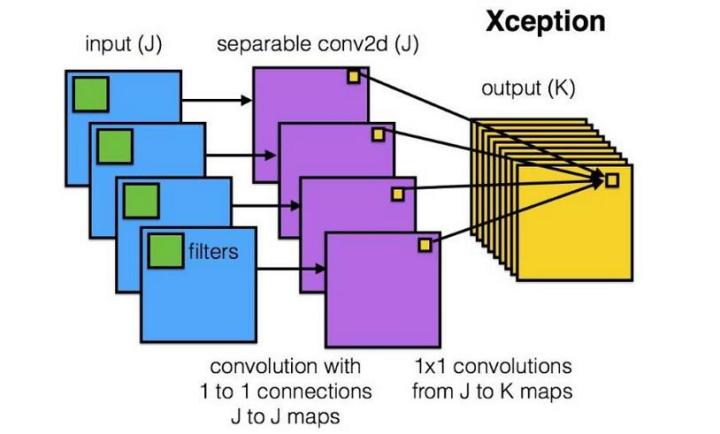
Xception网络就是基于上述问题发明而来的。我们首先对每个channel进行各自的卷积操作,有多个通道就有多少个过滤器。得到新的通道feature maps后,这时再对这批新的通道feature maps进行标准的1×1跨通道卷积操作。这种操作被称作“DepthWise convolution”操作.
该操作同样可以减少大量的参数,我们假设输入通道数为3,要求输出通道数为256,两种做法:
- 1.直接接一个3×3×256的卷积核,参数量为3×3×3×256=6,912
- 2.DW操作,分两步完成。参数量为1×3×3×3+3×1×1×256=795
因此,一个depthwise操作比标准的卷积操作降低不少参数,同时论文指出这个模型得到更好的分类效果。ShuffleNet
前面介绍了分组卷积,现在考虑随机分组。AlexNet的Group Convolution当中,特征的通道被平均分到不同组里,最后再通过两个全连接层来融合特征。这样一来只能在最后时刻才能融合不同组之间的特征,对模型的泛化性是相当不利的。为了解决这个问题,ShuffleNet每次层叠这种Group conv层前,都进行一次channel shuffle,shuffle过的通道被分配到不同的组中。进行完一次group conv之后,再一次channel shuffle,然后分到下一层组卷积中,以此循环。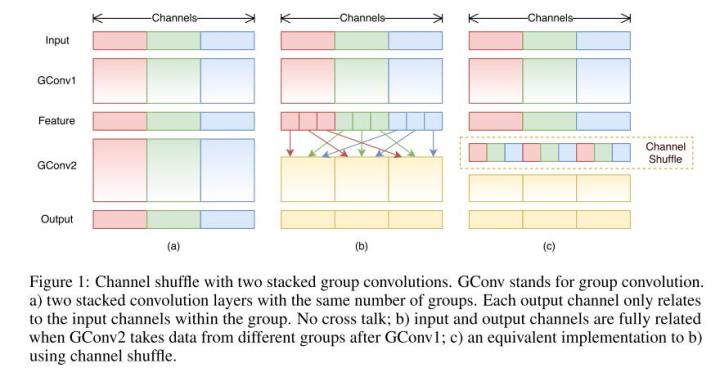
经过channel shuffle之后,Group conv输出的特征能考虑到更多通道,输出的特征自然代表性就更高。另外,AlexNet的分组卷积实际上是标准卷积操作,而在shuffleNet里面的分组卷积操作是depthwise,因此结合了通道洗牌和分组depthwise的卷积的ShuffleNet效果很好。
值得考虑的是ICCV2017入选论文:IGC(Interleaved Group Convolution),即通用卷积神经网络交错组卷积,形式上类似进行了两次组卷积
要注意的是,Group conv是channel 分组方式,depthwise+pointwise是卷积方式,只是在ShuffleNet中将这两种方式结合了起来。
SENet
如果一个channel表示的是一个特征,那么通道间的每个特征都是平等的么?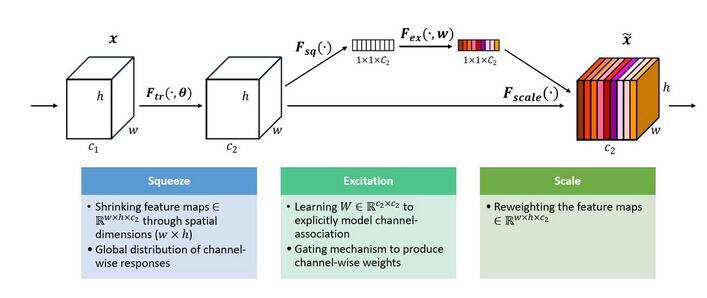
SENet就由此产生了。
一组特征在上一层中被输出,这时候分成两条路线,第一条直接通过,第二条首先进行Squeeze操作(Global Average Pooling)。然后进行Excitation操作,把这一列特征通道向量输入两个全连接层和sigmoid,建模出特征通道间的相关性,得到的输出其实就是每个通道对应的权重,把每个权重通过Scale乘法通道加权到原来的特征上(第一条路),这就完成了权重的分配
Dilated convolution
标准的3×3卷积核只能看到对应的3×3的区域大小,为了能让卷积核看到更大的范围,dilated conv使其成为了可能。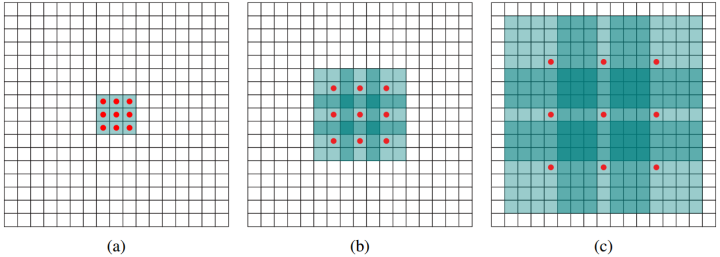
Deformable convolution 可变形卷积核
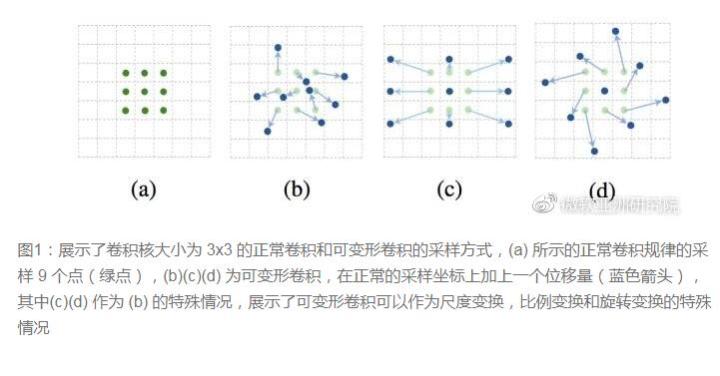
传统的卷积核一般都是长方形或正方形的,但MSRA提出了一个相当反直觉的见解,认为卷积核的形状是可变化的,变形的卷积核能让它只看到感兴趣的图像区域,这样识别出来的特征更佳。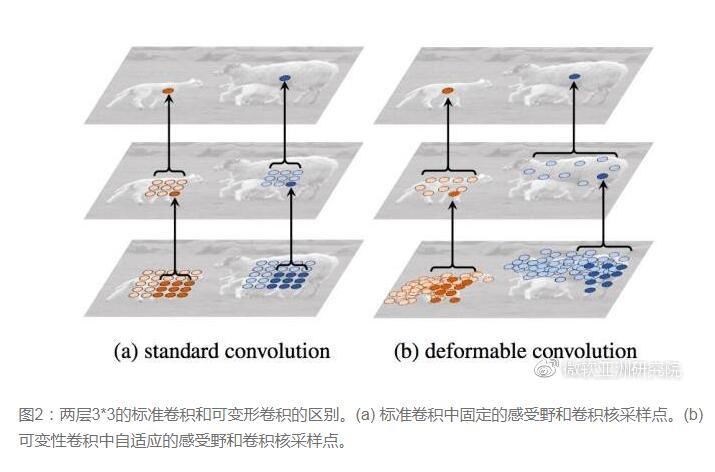
直接在原来的过滤器前面再加一层过滤器,这层过滤器学习的是下一层卷积核的位置偏移量(offset),这样只是增加了一层过滤器或者直接把原网络中的某一层过滤器当成学习offset的过滤器。这样实际增加的计算量是相当少的,但能实现可变形卷积核,识别特征的效果更好。