
尴尬
最近看别人做电影的推荐系统,用在输入用户特征和电影特征的时候用到了Embedding层,一开始疑惑了好久这里的embedding层是怎么做的,上网查了一下才发现是就是之前的word embedding. 望以后能学习致用!
Pytorch中的embedding
Pytorch中的embedding层非常简单的调用,torch.nn.Embedding(m,n),其中m表示单词的总数目,n表示词嵌入的维度。nn.Embedding 具有一个权重,形状是(m,n).
默认是随机初始化的1
2
3
4
5
6
7
8
9
10
11
12
13import torch
from torch import nn
from torch.autograd import Variable
# 定义词嵌入
embeds = nn.Embedding(2, 5) # 2 个单词,维度 5
# 得到词嵌入矩阵,开始是随机初始化的
torch.manual_seed(1)
embeds.weight
# 输出结果:
Parameter containing:
-0.8923 -0.0583 -0.1955 -0.9656 0.4224
0.2673 -0.4212 -0.5107 -1.5727 -0.1232
[torch.FloatTensor of size 2x5]
如果从使用已经训练好的词向量,则采用1
2pretrained_weight = np.array(args.pretrained_weight) # 已有词向量的numpy
self.embed.weight.data.copy_(torch.from_numpy(pretrained_weight))
embedding的读取
读取一个向量。
注意参数只能是LongTensor型的1
2
3
4
5
6
7# 访问第 50 个词的词向量
embeds = nn.Embedding(100, 10)
embeds(Variable(torch.LongTensor([50])))
# 输出:
Variable containing:
0.6353 1.0526 1.2452 -1.8745 -0.1069 0.1979 0.4298 -0.3652 -0.7078 0.2642
[torch.FloatTensor of size 1x10]
读取多个向量。
输入为两个维度(batch的大小,每个batch的单词个数),输出则在两个维度上加上词向量的大小。
Input: LongTensor (N, W), N = mini-batch, W = number of indices to extract per mini-batch
Output: (N, W, embedding_dim)
详解整个过程
Embeding层:
输入shape:(batchsize, sequence_length)
输出shape:(batchsize,embedding_dim)
事实上,我们这里提到的Embedding层在我们之前介绍的word embedding中也只是一部分模块。
看下面例子: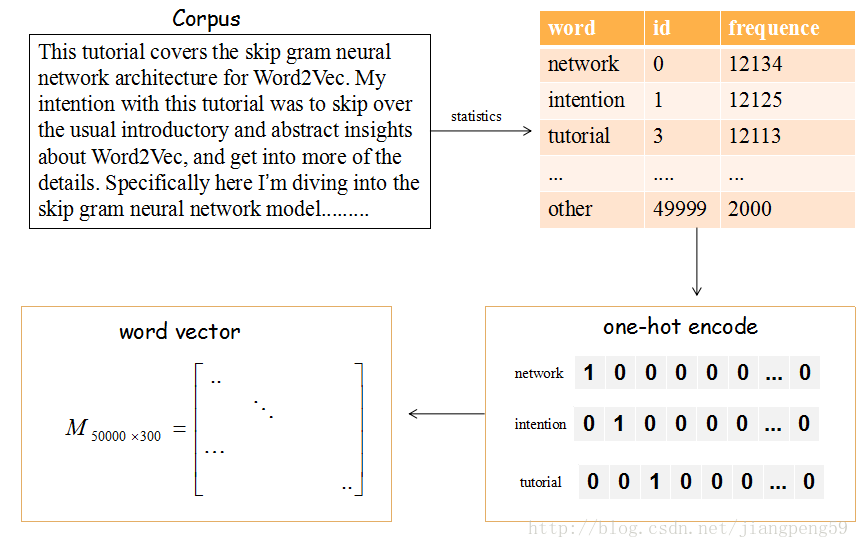
上图的流程是把文章中的单词使用词向量来表示。
(1)提取文章所有的单词,把所有单词降序排序(取前50000个,表示常出现的单词).
(2)每个编号ID都可以使用50000维的二进制(one-hot)表示
(3)最后,我们会产生一个矩阵M,行大小维词的个数5000,列大小为词向量的维度(嵌入的维度),比如矩阵的第一行就是编号ID=0,即network对应的词向量
那么这个矩阵怎么获得呢??在Skip-gram模型中,我们会随机初始化它,然后使用神经网络来训练这个权重矩阵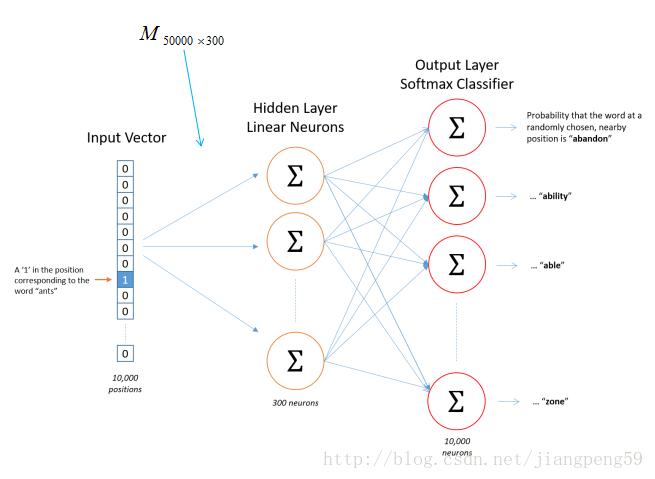
我们可以从上面的例中看到,我们所学习的embedding层是一个训练任务的一小部分,根据任务目标反向传播,学习到embedding层里的权重W.这个W是类似一种字典的存在,他能根据你输入的one-hot向量查到相应的Embedding vector.
Not Just Word Embeddings[2]
这些例子表明,词嵌入在自然语言处理中非常重要。它们允许我们捕捉语言中的关系,否则很难捕捉。然而,嵌入层可以用来嵌入比文字更多的东西。在我目前的研究项目中,我使用了嵌入层来嵌入在线用户行为。在本例中,我将索引分配给用户行为,如“门户Y上的页面类型X上的页面视图”或“滚动X像素”。然后使用这些索引构造用户行为序列。
通过与“传统”机器学习模型(SVM、随机森林、梯度增强树)和深度学习模型(深度神经网络、递归神经网络)的比较,我发现这种嵌入方法对于深度神经网络非常有效。
“传统的”机器学习模型依赖于一个表格式的输入,这是特征工程。这意味着,作为研究人员,我们要决定什么会变成一个特征。在这些情况下,功能可以是:访问主页的数量、完成的搜索数量、滚动的像素总量。然而,在进行特征工程时,很难捕捉空间(时间)维度。通过使用深度学习和嵌入层,我们可以通过提供一系列用户行为(作为索引)作为模型的输入来有效地捕获这个空间维度。
在我的研究中,门控回归单元/长-短期记忆的回归神经网络表现最好。结果非常接近。从“传统”特征工程模型来看,梯度增强树表现最好。我以后会写一篇关于这个研究的博文,更加详细。我想我的下一篇博客文章将更详细地探讨复发神经网络。
其他研究探索了如何利用嵌入层来编码mooc中的学生行为(Piech et al., 2016)和用户通过在线时尚商店的路径(Tamhane et al., 2017)。
Recommender Systems[3]
嵌入层甚至可以用来处理推荐系统中的稀疏矩阵问题。因为深度学习课程(fast.ai)使用推荐系统来介绍嵌入层,所以我也想在这里探讨它们。
推荐系统被广泛使用,你可能每天都会受到它们的影响。最常见的例子是亚马逊的产品推荐和Netflix的节目推荐系统。Netflix公司实际上是花了100万美元为他们的推荐系统寻找最佳协同过滤算法。您可以在这里看到其中一个模型的可视化。
推荐系统主要有两种类型,区分这两种推荐系统是很重要的。
基于内容的过滤。这种类型的过滤是基于关于项目/产品的数据。例如,我们让用户填写关于他们喜欢什么电影的调查。如果他们说他们喜欢科幻电影,我们推荐他们看科幻电影。在这种情况下,必须为所有项目提供大量元信息。
协作过滤:让我们找到其他喜欢你的人,看看他们喜欢什么,并假设你也喜欢同样的东西。喜欢你的人(用类似的方式评价你看过的电影的人)。在大型数据集中,这已经被证明比元数据方法更有效。从本质上说,询问人们的行为不如观察他们的实际行为好。进一步讨论这个问题是我们当中的心理学家应该做的。
为了解决这个问题,我们可以创建一个巨大的矩阵,所有用户对所有电影的评分。然而,在许多情况下,这将创建一个非常稀疏的矩阵。想想你的Netflix账户就知道了。你看过的连续剧和电影占他们总供应量的百分比是多少?这个比例可能很小。然后,通过梯度下降,我们可以训练神经网络来预测每个用户对每部电影的评价有多高。如果你想知道更多关于深度学习在推荐系统中的应用,请告诉我,我们可以一起进一步探讨。综上所述,嵌入层是惊人的,不应该被忽视。
如果你喜欢这篇文章,一定要推荐给其他人看。你也可以跟随这个档案,以跟上我的进程在快速AI课程。看到你在那里!
参考文献
1.keras:3)Embedding层详解
2.Piech, C., Bassen, J., Huang, J., Ganguli, S., Sahami, M., Guibas, L. J., & Sohl-Dickstein, J. (2015). Deep knowledge tracing. In Advances in Neural Information Processing Systems (pp. 505–513).
3.Tamhane, A., Arora, S., & Warrier, D. (2017, May). Modeling Contextual Changes in User Behaviour in Fashion e-Commerce. In Pacific-Asia Conference on Knowledge Discovery and Data Mining (pp. 539–550). Springer, Cham.
4.pytorch中的embedding词向量的使用