FCN 论文阅读
Summary
本文的重点在于构建”fully convolutional” network,该网络可以接收任意大小的输入并通过有效的推理和学习产生相应大小的输出.作者定义了一种新颖的架构,它将来自深层粗糙层的语义信息与来自浅层精细层的外观信息相结合,以生成准确而详细的部分。
从粗略推断到精细推断的下一步是对每个像素进行预测.
语义分割面临一个介于语义和位置的内在张力:当局部信息解决where,全局信息解决what.深度特征层次结构将位置和语义一同编码在local-to-global pyramid.作者又定义了一个全新的”skip”结构来将deep,coarse的语义信息和shallow,fine的外观信息结合起来.
全卷积网络
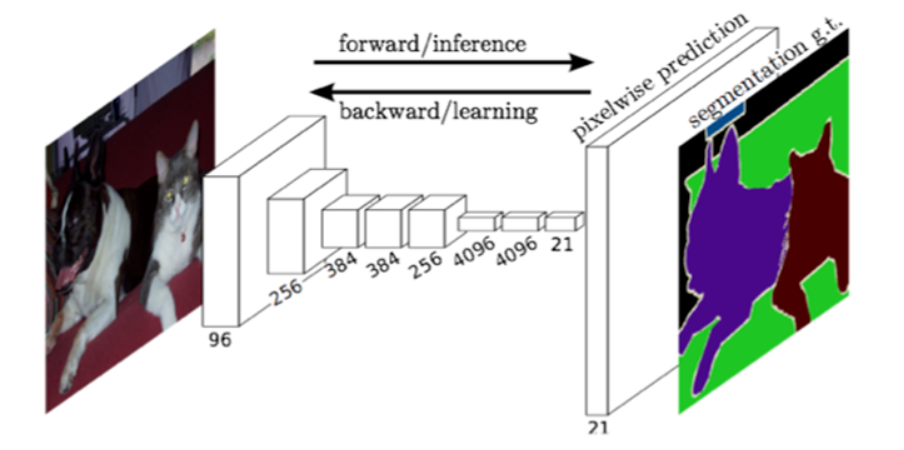
FCN对图像进行像素级的分类,从而解决了语义级别的图像分割.与传统的CNN在卷积层之后使用全连接层得到固定长度的特征向量,进行分类不同.FCN可以接收任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样,使它恢复到输入图像相同尺寸,从而可以对每个像素都产生了一个预测,同时保留了原始输入图像中的空间信息,最后在上采样的特征图上进行逐像素分类.
最后逐个像素计算softmax分类的损失函数,相当于每个像素对应一个训练样本
CNN强大之处在于它的多层结构能自动学习特征,并且可以学习到多个层次的特征:较浅的卷积层感知域较小,学习到一些局部区域的特征;较深的卷积层具有较大的感知域,能够学习到更加抽象的一些特征.
抽象的特征对分类很有帮助,可以很好地欧安段一幅图像中包含什么而类别的物体,但是因为丢失了一些物体的细节,不能很好地给出物体的具体轮廓、指出每个像素具体属于哪个物体,因此做到精确分割就很有困难.
把CNN改为FCN,输入一幅图像后直接在输出端得到dense prediction,也就是每个像素所属的class,从而得到一个end-to-end 的方法来实现image semantic segmentation。
传统的基于CNN的分割方法
为了对一个像素分类,使用该像素周围的一个图像块作为CNN的输入用于训练和预测.则会中方法有几个缺点:
- 存储开销很大
- 计算效率低下,相邻的像素快基本上都是重复的,针对每个像素块逐个计算卷积,这个计算也很大程度上存在重复
- 像素块大小的限制了感知区域的大小:通常像素块的大小比整幅图像的大小小很多,只能提取一些局部的特征,从而导致分类的性能受到限制
Dense prediction
全卷积FCN
全卷积FCN则是从抽象的特征中恢复出每个像素所属的类别,即从图像级别的分类进一步延伸到像素级别的分类
全连接层——>卷积层
经过多次卷积核Pooling之后,得到的图像越来越小,分辨率越来越低.FCN可以接收任意尺寸的输入图像,采用反卷积层对最后一个卷积层的特征图(feature map)进行上采样,使它恢复到输入图像相同的尺寸.
这里通过upsampling 得到dense prediction,作者研究过3种方案:
- shift-and-stitch
- filter rarefraction
- deconvolutional
Upsampling 上采样
一般得CNN结构中均是使用池化层来缩小输出图片得size,某些卷积层也参与到缩小图片size的过程,要想使输出的结果大小与输入图片的大小一样,我们就需要进行上采样,在caffe中被称为反卷积(deconvolution),也可能叫做转置卷积(conv_transpose)更为恰当一点.
反卷积的概念第一次出现在Zeiler在2010年发表的论文Devonvolutional networks中.
一般的卷积操作可以看作是一种矩阵运算:
例如,输入的特征图是4×4的X,我们要用3×3的卷积核对其进行卷积操作,
可以将卷积核写成上述形式,4×16的矩阵C,然后把输入特征展开为16×1的矩阵X,则可得到卷积操作后的输出为Y=CX.
通过上述的分析,可以知道卷积层的前向操作,将大的feature map 映射到小的feature map 可以通过Y=CX得到. 而反向操作是从小的feature map映射到大的feature map,而反卷积则是$X’=C’^TY$.
需要注意的是:这里的转置卷积矩阵的参数,不一定是从原始卷积矩阵中简单转置得到的,转置这个操作只是提供了转置卷积矩阵的形状而已.里面的参数仍是要由训练学习得到。
转置卷积操作构建了和普通的卷积操作一样的连接关系,只不过这个是从反向方向开始连接的。我们可以用它进行上采样。另外,这个转置卷积矩阵的参数是可以学习的,因此我们不需要一些人为预先定义的方法。即使它被称为转置卷积,它并不是意味着我们将一些现存的卷积矩阵简单转置并且使用其转置后的值。
上述提及的反卷积(转置卷积)的方法是一种upsampling 方法,还有一种方法是反池化(unpooling).
反池化就是池化的逆向过程,与池化一样不需要学习参数.
图(a)表示UnPooling的过程,特点是在Maxpooling的时候保留最大值的位置信息,之后在unPooling阶段使用该信息扩充Feature Map,除最大值位置以外,其余补0。与之相对的是图(b),两者的区别在于UnSampling阶段没有使用MaxPooling时的位置信息,而是直接将内容复制来扩充Feature Map。从图中即可看到两者结果的不同。图(c)为反卷积的过程,反卷积是卷积的逆过程,又称作转置卷积。最大的区别在于反卷积过程是有参数要进行学习的(类似卷积过程),理论是反卷积可以实现UnPooling和unSampling,只要卷积核的参数设置的合理。
Skip Archietecture
直接使用卷积核反卷积两个结果狗就可以得到结果了,但是直接将全卷积后的结果上采样后得到的结果通常是很粗糙的.所以skip结构主要是用来优化最终结果的.思路就是将不同池化层的结果进行上采样,然后结合这些结果来优化输出。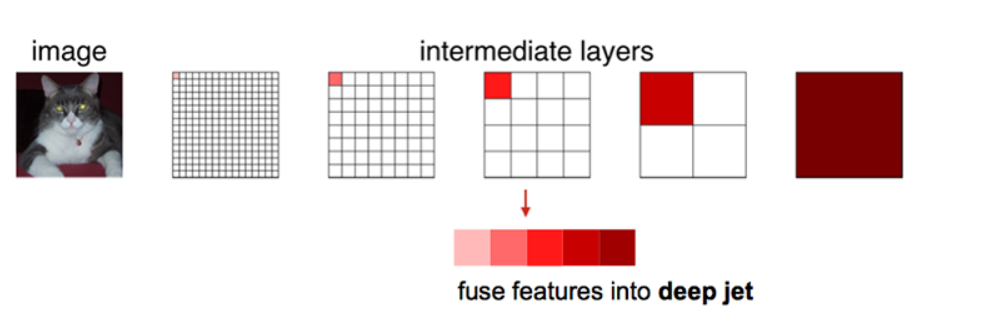
如上图所示,对原图像进行卷积conv1、pool1后原图像缩小为1/2;之后对图像进行第二次conv2、pool2后图像缩小为1/4;接着继续对图像进行第三次卷积操作conv3、pool3缩小为原图像的1/8,此时保留pool3的featureMap;接着继续对图像进行第四次卷积操作conv4、pool4,缩小为原图像的1/16,保留pool4的featureMap;最后对图像进行第五次卷积操作conv5、pool5,缩小为原图像的1/32,然后把原来CNN操作中的全连接变成卷积操作conv6、conv7,图像的featureMap数量改变但是图像大小依然为原图的1/32,此时图像不再叫featureMap而是叫heatMap。
现在我们有1/32尺寸的heatMap,1/16尺寸的featureMap和1/8尺寸的featureMap,1/32尺寸的heatMap进行upsampling操作之后,因为这样的操作还原的图片仅仅是conv5中的卷积核中的特征,限于精度问题不能够很好地还原图像当中的特征,因此在这里向前迭代。把conv4中的卷积核对上一次upsampling之后的图进行反卷积补充细节(相当于一个插值过程),最后把conv3中的卷积核对刚才upsampling之后的图像进行再次反卷积补充细节,最后就完成了整个图像的还原。
具体来说,就是将不同池化层的结果进行上采样,然后结合这些结果来优化输出,具体结构如下: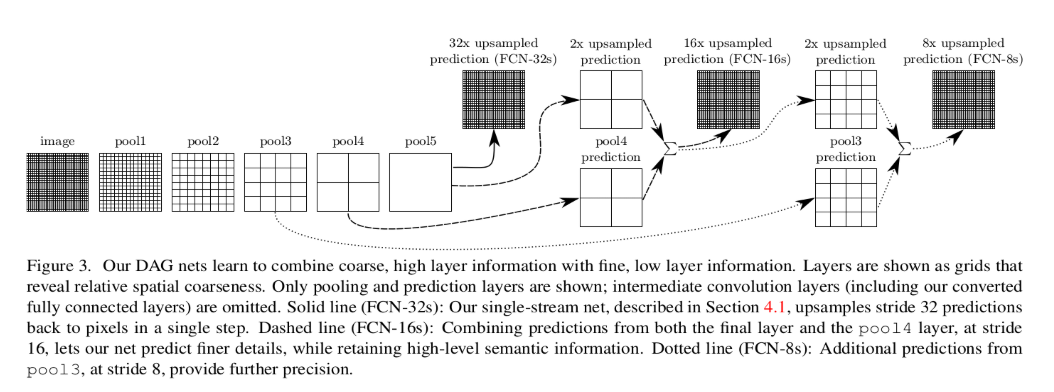
Patchwise training is loss sampling
术语“patchwise training”旨在避免完全图像训练的冗余。在语义分割中,假设你在对图像中的每个像素进行分类,通过使用整个图像,你在输入中添加了大量的冗余。在训练分割网络中避免这种情况的一种标准方法是从训练集而不是完整的图像中向网络提供批量的随机patches(围绕感兴趣的对象的小图像区域)。这种“patchwise抽样”确保输入具有足够的方差,并且是训练数据集的有效表示(小批处理应该与训练集具有相同的分布)。这种技术还有助于更快地收敛和平衡类。在这篇文章中,他们声称没有必要使用patcwise training,如果你想平衡类,你可以用权重或采样损失。从另一个角度来看,每个像素分割中完全图像训练的问题是输入图像具有很大的空间相关性。要修复这个问题,您可以从训练集中取样patches(Patchwise training),也可以从整个图像中采样loss。这就是为什么这一子节被称为“Patchwise training is loss sampling”。因此,通过“将损失限制在其空间项的随机采样子集内,将patches排除在梯度计算之外”。他们尝试了这种“loss sampling”,随机忽略最后一层的细胞,这样损失就不会在整个图像中计算出来。
在随机优化中,梯度计算是由训练分布支配的.patchwise训练和全卷积训练能被用来产生任意分布,尽管它们相对的计算效率依赖于重叠域和minibatch的大小.在每一个由所有的单元接收域组成的批次在图像的损失之下(或图像的集合),整张图像的全卷积训练等同于patchwise训练,当这种方式比patches的均匀取样更加高效的同时,它减少了可能的批次数量.然而在一张图片中随机选择patches,可能更容易被重新找到.限制基于它的空间位置随机取样子集产生的损失(或者可以说应用输入和输出之间的DropConnect mask)排除来自梯度计算的patches.
如果保存下来的patches依然有重要的重叠,全卷积计算依然将加速训练。如果梯度在多重逆推法中被积累,batches能包含几张图的patches。patcheswise训练中的采样能纠正分类失调 [30,9,3] 和减轻密集空间相关性的影响[31,17]。在全卷积训练中,分类平衡也能通过给损失赋权重实现,对损失采样能被用来标识空间相关
分割结构
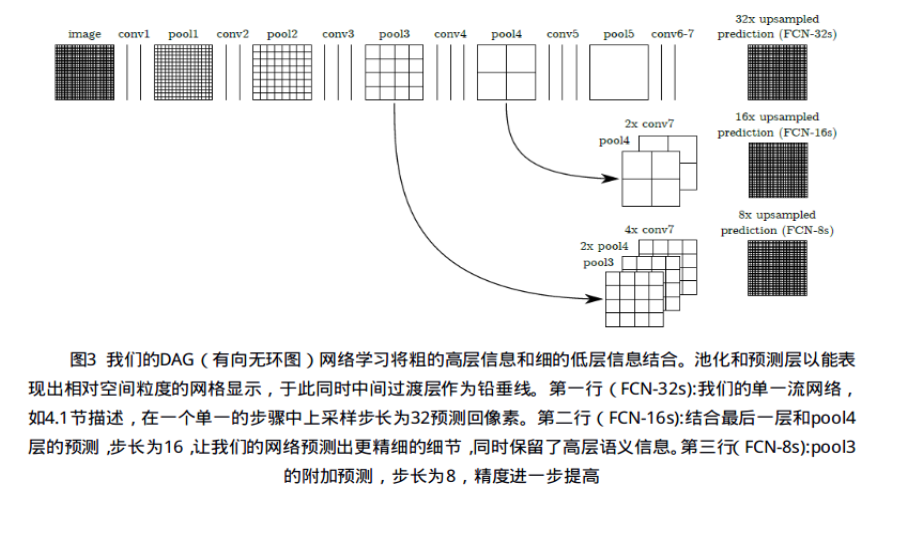
注:不是每个可能的patch被包含在这种方法中,因为最后一层单位的的接收域依赖一个固定的、步长大的网格。然而,对该图像进行向左或向下随机平移接近该步长个单位,从所有可能的patches 中随机选取或许可以修复这个问题。
FCN的缺点:
- 得到的结果还是不够精细,进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊核平滑,对图像中的细节不敏感
- 对各个像素进行分类,没有充分考虑像素与像素之间的关系,忽略了在通常的基于像素分类的分割方法种使用的空间规整(spatial regularization)步骤,缺乏空间一致性.
FCN代码实现
Onehot1
2
3
4
5def onehot(data,n):
buf=np.zeros(data.shape+(n,))
nmsk=np.arange(data.size)*n+data.ravel()
buf.ravel()[nmsk-1]=1
return buf
数据集准备1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48import torch
import torch.nn as nn
from torch.utils.data import DataLoader,Dataset,random_split
from torchvision import transforms
import cv2
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])
])
class BagDataset(Dataset):
def __init__(self,transform=None):
self.transform=transfom
def __len__(self):
return len(os.listdir('bag_data'))
def __getitem__(self,idx):
img_name=os.listdir('bag_data')[idx]
imA=cv2.imread('bag_data/'+img+name)
imA=cv2.resize(imA,(160,160))
imB=cv2.imread('bag_data_msk/'+img_name,0)
imB=cv2.imread(imB,(160,160))
imB=imB/255
imB=imB.astype('uint8')
imB=onehot(imgB,2)
imB=imB.transpose(2,0,1)
imB=torch.FloatTensor(imB)
if self.transform:
imA=self.transform(imA)
return imA,imB
bag=BagDataset(transform)
train_size=int(0.9*len(bag))
test_size=len(bag)-train_size
train_dataset,test_dataset=random_split(bag,[train_size,test_size])
train_dataloader=DataLoader(train_dataset,batch_size=4,shuffle=True,num_workers=4)
test_dataloader=DataLoader(test_dataset,batch_size=4,shuffle=True,num_workers=4)
if __name__=='__main__':
for train_batch in train_dataloader:
print(train_batch)
for test_batch in test_dataloader:
print(test_batch)
训练1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74def train(epo_num=50,show_vgg_params=False):
device=torch.device("cuda" if torch.cuda.is_available() else 'cpu')
vgg_model=VGGNet(requires_grad=True,show_params=show_vgg_params)
fcn_model=FCNs(pretrained_net=vgg_model,n_class=2)
fcn_model=fcn_model.to(device)
criterion=nn.BCELoss().to(device)
optimizer=optim.SGD(fcn_model.parameters(),lr=1e-2,momentum=0.7)
all_train_iter_loss=[]
all_test_iter_loss=[]
prev_time=datetime.now()
for epo in range(epo_num):
train_loss=0
fcn_model.train()
for index,(bag,bag_msk) in enumerate(train_dataloader):
bag=bag.to(device)
bag_msk=bag_msk.to(device)
optimizer.zero_grad()
output=fcn_model(bag)
output=torch.sigmoid(output)
loss=criterion(output,bag_msk)
loss.backward()
iter_loss=loss.item()
all_train_iter_loss.append(iter_loss)
train_loss+=iter_loss
optimizer.step()
output_np=output.cpu().detach().numpy().copy()
output_np=np.argmin(output_np,axis=1)
bag_msk_np=bag_msk.cpu().detach().numpy().copy()
bag_msk_np=np.argmin(bag_msk_np,axis=1)
if np.mod(index,15)==0:
print('epoch {},{}/{},train loss is {}'.format(epo,index,len(train_dataloader)))
test_loss=0
fcn_model.eval()
with torch.no_grad():
for index,(bag,bag_msk) in enumerate(test_dataloader):
bag=bag.to(device)
bag_msk=bag_msk.to(device)
optimizer.zero_grad()
output=fcn_model(bag)
output=torch.sigmoid(output)
loss=criterion(output,bag_msk)
iter_loss=loss.item()
all_test_iter_loss.append(iter_loss)
test_loss+=iter_loss
output_np = output.cpu().detach().numpy().copy() # output_np.shape = (4, 2, 160, 160)
output_np = np.argmin(output_np, axis=1)
bag_msk_np = bag_msk.cpu().detach().numpy().copy() # bag_msk_np.shape = (4, 2, 160, 160)
bag_msk_np = np.argmin(bag_msk_np, axis=1)
if np.mod(index, 15) == 0:
print(r'Testing... Open http://localhost:8097/ to see test result.')
cur_time=datetime.now()
h,remainder=divmod((cur_time-prev_time).seconds,3600)
m,s=divmod(remainder,60)
time_str="Time %02d:%02d:%02d"%(h,m,s)
prev_time=cur_time
print('epoch train loss = %f, epoch test loss = %f, %s'
%(train_loss/len(train_dataloader), test_loss/len(test_dataloader), time_str))
if np.mod(epo, 5) == 0:
torch.save(fcn_model, 'checkpoints/fcn_model_{}.pt'.format(epo))
print('saveing checkpoints/fcn_model_{}.pt'.format(epo))
网络结构
1 | class FCN32s(nn.Module): |
这里FCN32s是最原始的FCN的结构,没有运用skip结构。
然而FCN32s得到的结果比较粗糙,为此引入了skip结构,也就是形成了FCN16s的结构.
从上面图可以看出来,FCN16s只用了一个skip结构,FCN8s用了2个skip结构,而在FCNs里对每个上采样后的特征图用了skip结构,将这些上采样后的特征图与之前的卷积后的特征图融合(采用的是加法操作).
在FCN的基础上,UCLA DeepLab的Liang-Chieh Chen[2][2]等在得到像素分类结果后使用了全连接的条件随机场(fully connected conditional random fields),考虑图像中的空间信息,得到更加精细并且具有空间一致性的结果
条件随机场(CRF)是我们常会在以深度学习为框架的图像语义分割系统中看到,这项技术常作为输出结果的优化后处理手段.并且类似类似的技术很多,比如还有马尔可夫随机场(MRF)和高斯条件随机场(G-CRF),但原理都较为类似.FCN是像素到像素的映射,所以最终输出图片上的每一个像素都是标注了分类的,将这些分类简单地看成是不同的变量,每个像素都和其他像素之间建立一种连接,连接也就是相互间的关系