
Deep Neural Networks for Object Detection
简介
在本文中,作者利用DNNS的强大功能来解决目标检测问题,不仅对对物体进行分类还试图精确定位物体.
本文提出了一个简单而强大的object detection公式通过用回归问题处理覆盖对象的包围框。并且文中定义了一个多尺度推理过程,它能够以较低的成本由少数网络应用产生高分辨率的目标检测(object detection).该方法在Pascal VOC上展示了最先进的性能.
在这篇文章中,作者证明了基于DNN的回归能够学习特征,这不仅有利于分类,而且能够捕捉到较强的几何信息。我们使用AlexNet引入的分类通用架构,并用回归层替换最后一层。有点令人惊讶但却很有说服力的见解,网络在某种程度上编码了translation invariance,也可以捕获对象的位置。
其次,作者介绍了一个多尺度框(box)推理,然后是一个细化步骤,以产生精确的检测。通过这种方式,我们能够应用DNN来预测低分辨率的mask,受输出层大小的限制,以低成本获得像素级的精度——网络对每个输入图像只应用几十次.
此外,提出的方法非常简单。没有必要手工设计一个模型来明确地捕捉部件及其关系。这种简单性的优点是易于应用于广泛的类,而且在更广泛的对象(刚性对象和可变形对象)中显示出更好的检测性能。
Related Work
物体检测研究最广泛的范例之一是基于可变形部件的模型,其中DPM(Discriminatively Trained Partbased Models)是最突出的例子。这种方法将一组经过鉴别训练的部件组合在一个称为图形结构的星形模型中。它可以被认为是一个两层模型-parts是第一层,star model是第二层。与DNNs(其层是通用的)相反,DPM的工作利用了领域知识——部件基于人工设计的梯度直方图(HOG)描述符,部件(parts)的结构是由运动学驱动的。
用于物体检测和解析的深度架构是由基于部分的模型驱动的,传统上称为复合模型,其中物体被表示为图像原语的分层组合。一个值得注意的例子是And/Or图,其中一个物体由树建模,其中And节点表示不同部分,Or节点表示同一部分的不同模式。与DNNs类似,And/Or图由多个层组成,其中低层表示小的通用图像原语,而高层表示物体部分。这种合成模型比神经网络更容易解释。另一方面,它们需要推理,而本文所考虑的DNN模型是纯前馈的,没有潜在变量需要推理。
用于检测的复合模型的进一步示例是基于基本(primitives)的片段、关注形状[13]、使用Gabor过滤器[10]或更大的HOG过滤器[19]。这些方法传统上受到训练困难和使用专门设计的学习程序的挑战。此外,在推理时,它们结合了自底向上和自顶向下的过程。
神经网络(NNs)可以被认为是一种比上述模型更具有通用性和可解释性的组合模型。神经网络在视觉问题上的应用已有几十年的历史,卷积神经网络是最突出的例子。直到最近,这些模型才以DNNs的形式在大规模图像分类任务中取得了巨大的成功。然而,它们在检测方面的应用是有限的。场景解析作为一种更为详细的检测形式,已经尝试使用多层卷积神经网络进行检测。医学图像的分割已经解决了通过使用DNNs。然而,这两种方法都使用神经网络作为超像素或每个像素位置上的局部或半局部分类器。然而,作者的方法使用完整的图像作为输入,并通过回归进行定位。因此,它是神经网络更有效的应用。
也许最接近我们的方法是《Object-class segmentation using deep convolutional neural networks》,它具有类似的高级目标,但使用的网络要小得多,具有不同的特性、loss函数,并且没有机制来区分同一类的多个实例。
DNN-based Detection
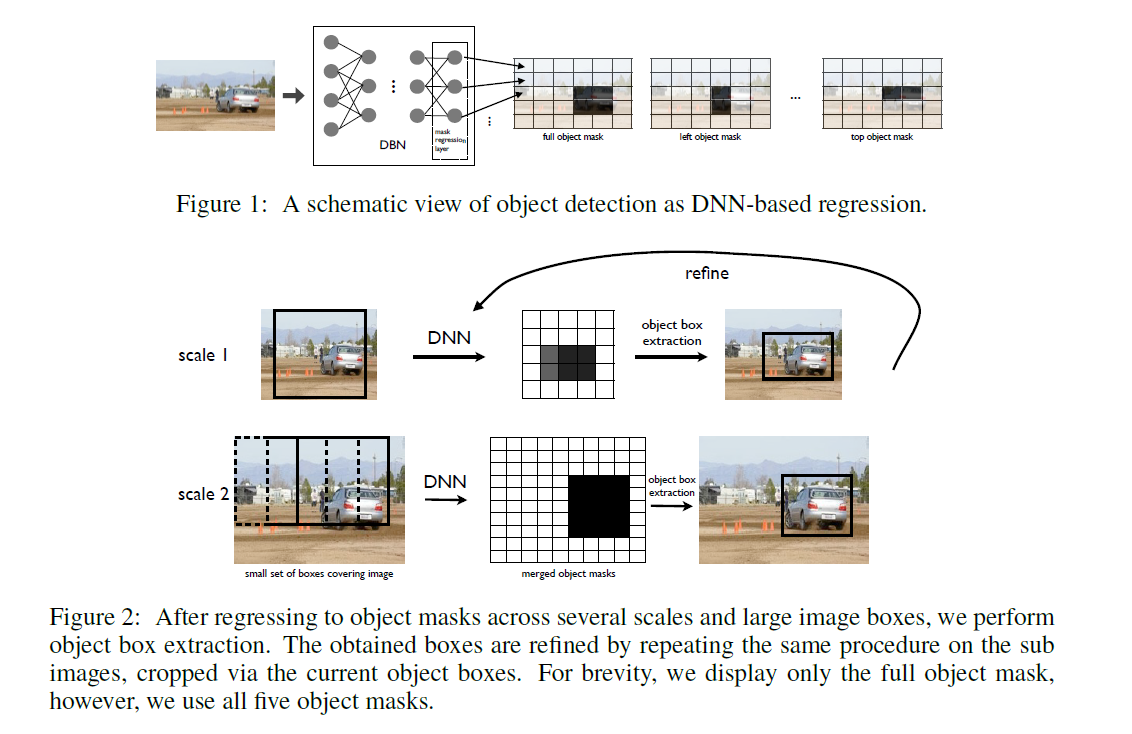
我们的方法的核心是基于DNN的对象掩码(mask)回归,如图1所示。基于这个回归模型,我们可以为整个对象以及部分对象生成掩码。单次DNN回归可以得到图像中多个对象的掩码。为了进一步提高定位的精度,我们将DNN定位器应用于一组较小的大型子窗口上。整个流程如图2所示,如上图所示。
Detection as DNN Regression
这里的网络是基于AlexNet定义的卷积DNN。它总共由7层组成,前5层是卷积的,后2层是完全连接的。每一层使用一个修正的线性单元(ReLU)作为非线性变换。其中三个卷积层还有最大池。有关更多细节,请参阅[14]。
我们将上述通用体系结构用于局部化。我们不再使用softmax分类器作为最后一层,而是使用回归层来生成目标二进制掩码DNN$(x;\theta)∈R^n$,其中$\theta$为网络参数,N为像素总数。因为网络的输出一个固定的维度,我们预测一个固定大小的mask: N=d×d。调整后的图像大小,由此产生的二进制mask代表一个或多个对象:如果这个像素位于给定类的对象的边界框内它应该为特定的像素值1,其他为0。
该网络通过最小化用于预测表示图像x的ground truth mask $m∈[0,1]^N$的L2误差:
其中求和范围是整个图像训练集D包括物体的边界框
由于基网络是高度非凸的,且不能保证最优性,因此有时需要根据ground truth mask对每个输出使用不同的权值来正则化损失函数。直观的感觉是,相对于图像大小,大多数对象都很小,而且网络很容易陷入为每个输出分配零值的简单解决方案。为了避免这种不受欢迎的行为,通过一个参数$\lambda∈R^+$,将ground truth mask中对应于非零值的输出的权值增加这是有帮助的。如果$\lambda$选择的值较小,那么ground truth值为0的输出上的错误受到的惩罚要明显小于值为1的输出上的错误,因此即使信号较弱,也鼓励网络预测非零值。
在我们的实现中,我们使用接受域为225×225的网络,并输出一个大小为d×d的掩码(mask),使d=24
Precise Object Localization via DNN-generated Masks
尽管所提出的方法能够生成高质量的掩码(mask),但是还存在一些额外的挑战。首先,单个对象掩码(mask)可能不足以消除相邻对象之间的歧义。其次,由于输出大小的限制,我们生成的掩码比原始图像的大小小得多。例如,对于大小为400×400且d=24的图像,每个输出将对应于大小为16×16的单元格,这将不足以精确定位对象,尤其是在对象很小的情况下。最后,由于我们使用完整的图像作为输入,小的物体会影响很少的输入神经元,因此很难识别。下面,我们将解释如何处理这些问题。
Multiple Masks for Robust Localization
为了处理多个触摸对象,我们生成的不是一个而是多个掩码,每个掩码表示整个对象或其中的一部分。由于我们的最终目标是生成一个边界框,所以我们使用一个网络来预测对象框掩码,并使用四个额外的网络来预测该框的四个部分:底部、顶部、左侧和右侧的一半,都定义为$m^h$、h∈{full,bottom,top,left}。这五个预测过于完整,但有助于减少不确定性,并在某些mask下处理错误。此外,如果将相同类型的两个对象相邻放置,那么在生成的五个掩码中,至少有两个掩码不会合并对象,从而消除它们的歧义。这将允许检测多个对象。
在训练时,我们需要将对象框转变为5个mask.因为这些mask是比原图更小,所以为我们需要缩小ground truth mask的尺寸到network输出的大小.图像中出现表示对象的长方形用T(i,j)表示,可以用网络的输出(i,j)来预测.该长方形的左上角在$(\frac{d_1}{d}(i-1),\frac{d_2}{d}(j-1))$并且大小变为$\frac{d_1}{d}×\frac{d_1}{d}$,其中d是输出mask的大小,并且$d_1,d_2$是图像的高和宽.在训练期间,我们设值m(i,j)被预测作为T(i,j)的部分被box bb(h)覆盖:
其中bb(full)对应于ground truth object box。对于h的剩余值,bb(h)对应原来box的4个半(four halves)
注意,我们使用完整的对象框以及框的顶部、底部、左侧和右侧的halves来定义总共五种不同的覆盖类型。groundtruth box bb的$m^h(bb)$结果用于h型网络的训练时。
此时,应该注意的是,可以为所有掩码训练一个网络,其中输出层将生成所有五个掩码。这将支持可伸缩性。通过这种方式,5个局部化器将共享大多数层,从而共享特性,这看起来很自然,因为它们处理的是相同的对象。一种更激进的方法——对许多不同的类使用相同的局部化器——似乎也可行。
Object Localization from DNN Output
为了完成检测过程,我们需要估计每个图像的一组边界框。尽管输出分辨率小于输入图像,但我们将二进制掩码重新缩放为输入图像的分辨率。目标是估计边界框bb = (i,j,k,l)由它们的左上角(i,j)和右下角(k,l)在输出掩码坐标中。
为了做到这一点,我们使用分数S表示每个带mask的边界框bb的一致,并推断出得分最高的框。一个自然的约定是测量mask所覆盖的边框部分:
其中求和所有网络的输出下标(i,j)并且m=DNN(x)为网络的输出.如果我们扩展上上述分数在5个mask类,最终的分数可以读为:
其中halves={full,bottom,top,left,left}下标整个box和它的四个halves.对于h表示halves的一个,$\overline{h}$表示h的相对的half,例如一个top mask应该很好的被一个top mask覆盖,而跟bottom mask没有一点接触.对于h=full,我们指定$\overline{h}$为bb周围的一个长方向区域,它的分数会被惩罚如果full mask 拓展出了bb.在上述求和里,box的分数将会很大如果5个mask都是一致的。
我们使用等式(3)的分数来穷尽搜索所有可能的边界框的集合.我们考虑平均图像维数等于[0.1,0.2,…,0.9]和10个由对象框的k-means估计的不同的纵横比的边界框。在图像中我们划过上述90个boxes使用5像素的stride。注意,等式(3)的分数能被有效地计算通过使用4步操作,在图像的mask被计算以后.运算的精确数是5(2×#pixels+20×#boxes).其中第一项计算了mask计算的复杂度,而第二项解释了box分数的计算.
为了生成最终的检测集,我们执行两种类型的过滤。第一种是保持等式2定义的强分值框,例如大于0.5。我们通过在感兴趣的类上训练AlexNet的DNN分类器对它们进行进一步的修剪,并保留正分类的关于到当前检测器的类。最后,我们采用了《Object detection with discriminatively trained part-based models》中的非最大抑制。
Multi-scale Refinement of DNN Localizer
解决网络输出分辨率不够的问题有两种方法:(i)在几个尺度和几个大的子窗口上应用DNN定位器;(二)利用DNN定位器对top推断的边界框进行检测细化(见图2)。
使用不同尺度的大窗口,我们生成几个mask,并将它们合并成高分辨率的mask,每个mask对应一个尺度。合适的尺度的范围取决于图像的分辨率和定位器的接受域(感受野)的大小——我们想要的图像由网络输出操作在更高的分辨率,同时我们希望每个对象属于至少一个窗口,这些窗口的数量很小。
为了实现上述目标,我们使用了三种尺度:全图和另外两种尺度,即给定尺度下窗口的大小是上一尺度下窗口大小的一半。我们在每个尺度上用窗口覆盖图像,使这些窗口有一个小的重叠——它们的面积的20%。这些窗口的数量相对较小,可以覆盖图像的多个尺度。最重要的是,最小尺度的窗口允许更高分辨率的局部化。
在推理时,我们将DNN应用于所有窗口。请注意,它与滑动窗口方法有很大的不同,因为我们需要对每个图像计算少量窗口,通常少于40个。在每个尺度上生成的对象mask通过最大操作进行合并。这给我们提供了图像大小的三个mask,每个mask“看着”不同大小的物体。对于每个比例,我们应用5.2节中的边界框推断来得到一组检测结果。在我们的实现中,我们使用每个尺度的前5个检测结果,总共15个检测结果。
为了进一步改进定位,我们经历了DNN回归的第二个阶段,称为细化。DNN定位器应用在初始检测阶段定义的窗口上——15个边界框中的每一个都被放大1.2倍并应用到网络上。高分辨率定位器(localizer)的应用大大提高了检测的精度。
DNN Training
我们的网络的一个引人注目的特点是它的简单性:分类器被简单的mask生成层代替,没有任何平滑的先验或卷积结构。然而,它需要使用大量的训练数据进行训练:几乎每个位置都需要出现不同大小的对象。
为了训练mask生成器,我们从每张图像中生成数千个样本,分为60%的阴性样本和40%的阳性样本。如果一个样本不相交于任何感兴趣的对象的边界框,则认为它是负的。正样本是那些覆盖部分对象边界框至少80%区域的样本。对作物进行采样,使其宽度均匀分布在规定的最小尺度与整幅图像的宽度之间。
我们使用类似的准备步骤来训练用于最终修剪检测的分类器。同样,我们从每张图像中抽取数千个样本:60%的阴性样本和40%的阳性样本。负样本的边框与任何ground truth对象框有小于0.2 Jaccard-similarity .正样本必须至少有0.6相似的对象边界框并且标签上使用最相似的对象边界框的所指向的类。添加额外的负类作为正则化器并提高过滤器的质量。在这两种情况下,每个类的样本总数都选择为1000万。
由于定位的训练比分类更难,所以从具有高质量的低级过滤器的模型的权重开始是很重要的。为了实现这一点,我们首先训练网络进行分类,并重用除了分类器之外的所有层的权重进行定位。对于定位,我们对整个网络进行了微调,包括卷积层。
利用ADAGRAD对网络进行随机梯度训练,自动估计各层的学习率。