
2019.4.10:
感觉自己这篇好渣啊,特此修改
Attention的发展
Attention首先起源于视觉图像领域,早在上世纪九十年代就提出来了.但现在的attention,主要指深度学习出现以后的attention.(之前做过的基于脉冲神经网路的工作记忆的研究也有用到attention,不过与这儿的不太一样,在生物学和心理学上可能更多的是把attention视为一种资源.)
其实将attention对应到传统的NLP中的问题上,就是要解决对齐的问题.
Attention的对齐计算公式
说到底这些公式就是在算一个attention score,也就是权重.
Recurrent Models of Visual Attention
该文主要还是借鉴于人类的注意力的机制,我们人看东西并非将目光放在整张图上,尽管有时候会从总体上对目标进行把握,但是也是将目光按照某种次序(例如,从上到下,从左到右等)在图像上进行扫描,然后从一个区域转移到另一个区域.这么一个个的区域就是定义的part,或者说是glimpse。然后将这些区域的信息结合起来用于整体的判断和感受.
总结下来就是这个模型是一个recurrent neural network(RNN),按照时间顺序处理输入,一次在一张图像中处理不同的位置,逐渐地将这些部分信息结合起来,来建立一个该场景或环境的动态间隔表示.并非马上处理整张图像甚至bbox,在每一个步骤中,模型基于过去的信息和任务的需要选择下一个位置进行处理.这样就可以控制模型的参数和计算量,使之摆脱输入图像的大小的约束.这里和CNN有明显不同.本文就是要描述一个端到端的优化序列,能够直接训练模型,最大化性能衡量,依赖于该模型在整个任务上做的决策.利用反向传播来训练神经网络的成分和策略梯度来解决the non-differentiabilities due to the control problem.
本文将attention problem看作是目标引导的序列决策过程,能够和视觉环境交互. 在每个时间点,agent只能根据有带宽限制的感知器来观察全局,只能在一个局部区域或者狭窄的频域范围进行信息的提取.The agent可以自主的控制如何布置感知器的资源,即:选择感知的位置区域.该agent也可以通过执行actions来影响环境的真实状态.由于该环境只是部分可观察,它需要额外的信息来辅助其进行决定如何移动和如何最有效布置感知器.每一步,agent都会收到奖励或者惩罚,agent的目标就是奖励最大化.
模型: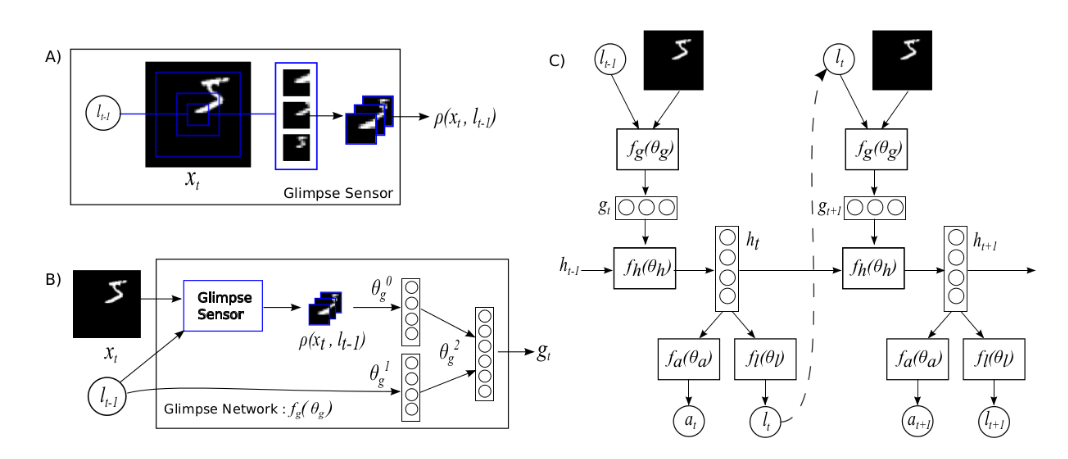
在每一个步骤t,该agent接收部分观察,没有处理全幅图像的权限,但是可以通过感知器p来提取从$x_t$得到的信息;假设从$L_{t-1}$提取的类似视网膜表示$p(x_t,l_{t-1})$,该表示比原始图像x维度低,我们称之为glimpse.有一个叫glimpse network$f_g$的网络结构包含$glimpse senseor$来产生glimpse feature vector $g_t$,见上面的B图.
显然,我们这里可以把$l_t$视为一种attention.
网络架构示意图: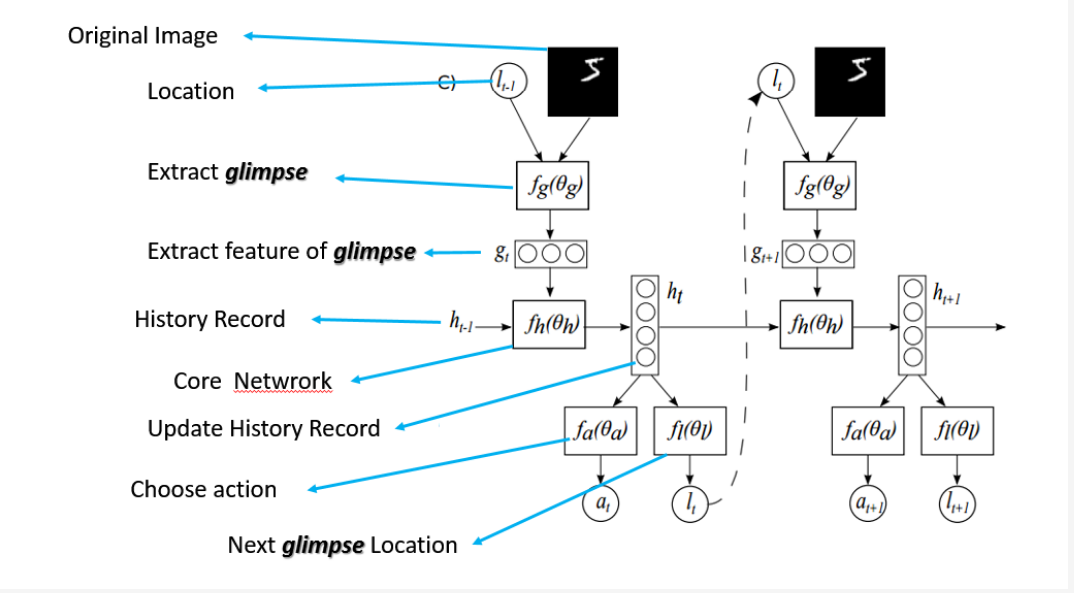
可以看出,这里的attention model的输入是一个图像,根据任务的需要,可以输出一系列的图像patch,即attention region,仅仅对这些图像patch进行处理,一方面可以减少非必要信息的干扰,降低噪声的影响,然后还可以减少计算量.
Soft and Hard attention
《show, Attend and Tell: Neural Image CaptionGeneration with Visual Attention》
Attention-based RNN in NLP
Neural Machine Translation by Jointly Learning to Align and Translate
这是NLP中第一个使用attention机制的工作.它们把attention机制用于神经机器翻译(NMT)中,NMT实际上就是一个典型的seq2seq模型,也就是encoder-decoder模型,传统的NMT使用两个RNN,一个RNN对源语言进行编码,将源语言编码到一个固定维度的中间向量,然后在使用一个RNN进行解码翻译到目标语言,传统的模型如下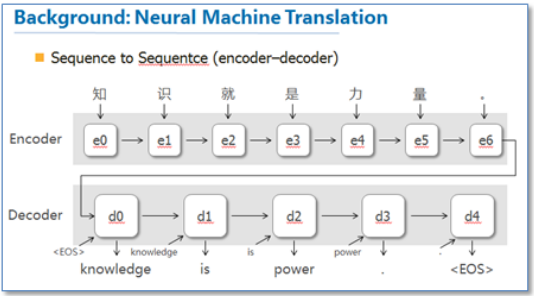
而该文提出的带有attention机制的NMT,模型如下: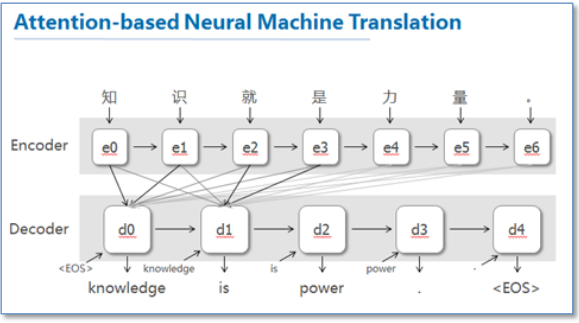
可以看出其意思是,在传统的NMT模型的基础上,把源语言端的每个词学到的表达(传统的只有最后一个词后学到的表达)和当前要预测翻译的词联系起来,这样的联系就是通过它们设计的attention进行的.做法上的区别是,它不是将encoder信息压缩到固定维度的向量而是将source sentences用一系列的向量来表示(各个时间点的hidden state),然后从中选择一部分和当前预测target最相关的词,在这个基础上进行预测.通过这种操作,可以使模型不用去压缩源信息,解决了更长的信息保留问题
一般的Encoder是一个RNN,其公式如下:
其中$h_t$是encoder在t时刻的hidden-state,C是由这些hidden-state最后生成的一个代表全句子的vector.
而传统的Decoder的表达式为:
(所以常常我们在写代码的时候,输出是log_softmax+NLLLoss或者可以用Cross_entropy来代替上述两者.)
这里的条件概率被建模为$p(y_t|\{y_1,..y_{t-1}\},c)=g(y_{t-1},s_t,c)$
也就是说在Decoder预测每一个$y_i$时,使用的是之前的时间步的结果$y_{<i}$与c.这里的c就是之前encoder输出的固定维度的向量,传统方法中这个c对于每个$y_i$都是一样的。
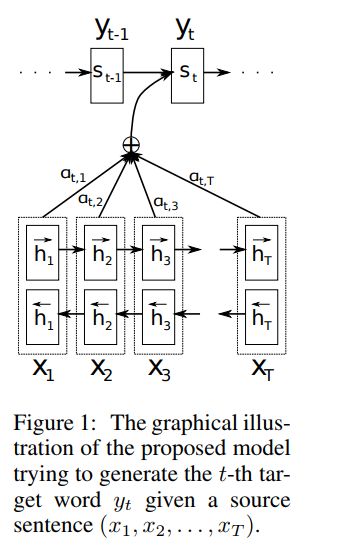
而作者的模型是:
其中$z_i$表示Decoder中RNN的隐层状态
并且这里将源语言端上下文向量表示由原来的c变成了$c_i$.即对每一个目标词$y_i$都有一个特定的上下文$c_i$与之对应.
模型大致结构如下图: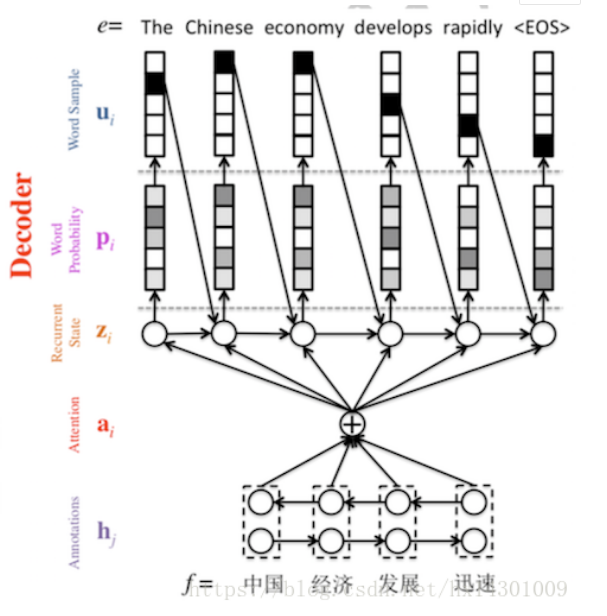
其中上下文向量$c_i$依赖于每个$h_j$
而$h_j$到$c_i$的权重通过下式得到:
attention在NLP中的核心意义就是对齐,如上所示,这种对齐是对输入向量位置j附近的表达与输出向量位置i附近(实际上是i-1的hidden)的表达的打分。
Effective Approaches to Attention-based Neural Machine Translation
论文中提出了两种attention,一种是global attention,一种是local attention.前者与上文相似,作者还新增了一些score function。最后实验结果是general的attention效果最好.如下图所示.之所以称为global,是因为它对源语言所有词进行处理。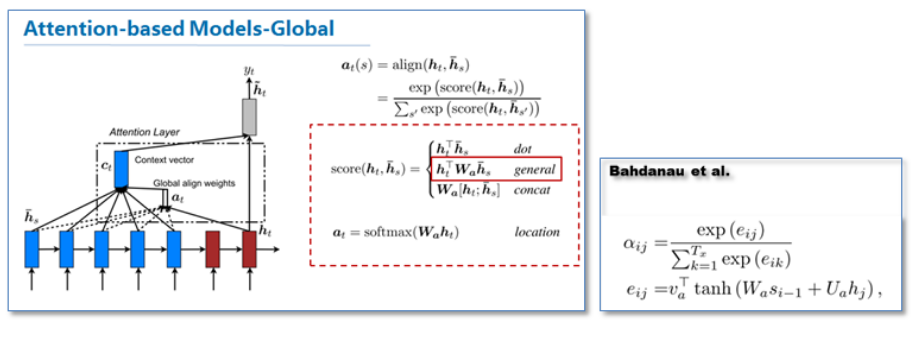
我们再来看一下local版本.主要思路是为了减少attention计算时的耗费.作者在计算attention时并不是去考虑源语言端的所有词,而是根据一个预测函数,先预测当前解码时要对齐的源语言端的位置$P_t$,然后通过上下文窗口,仅考虑窗口内的词.(先预测,解码器当前词在源语言上的位置,然后根据该位置开一个上下文窗口,再进行类似前面的attention操作)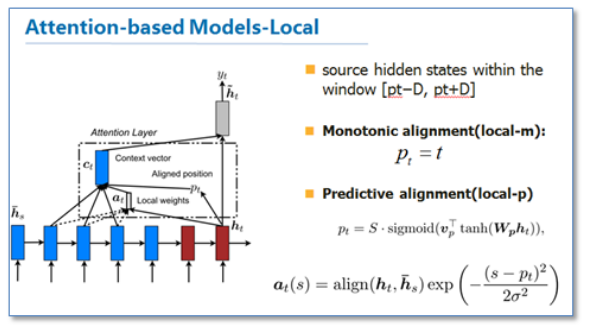
局部的Attention针对t时刻的输出生成一个它在源语言端的对齐位置,接着在源语言端取一个窗口$[P_t-D,P_t+D]$,上下文向量$c_t$就是通过计算窗口内的隐层状态的weighted sum获得(如果窗口>句子长度,则以句子长度为基准)。而D按照经验设定.
如何确定$P_t$,文章给了两种方式:
Monotonic alignment(local-m)——简单地设定$P_i$=i.
Predictive alignment(local-p)——即针对每个目标输出,预测它在源语言端地对齐位置,计算公式如下:
其中$W_p$与$V_p$都是模型学习地参数,T是源语言地句子长度.
最后,文章引入一个服从$N(p_i,\frac{D}{2})$的高斯分布来设置对其权重,因为直觉上,我们认为对齐位置$P_i$越近的地方,影响应该越大,这样目标位置i与源语言端位置j的对齐概率计算公式为:其中$align(z_i,h_j)$与前面计算方式相同
Attention-based CNN in NLP
本文是结合了卷积神经网络CNN与Attention机制,应用到文本分类中.
在一些自然语言处理任务中,构建合理的句子是非常关键的.比如QA问题中,匹配问题和答案.从问题中抽取关键的决定性的词语,去匹配合理的答案.
主要思路
- BCNN(Basic Bi-CNN)结构:使用基本CNN网络(无attention机制),每次处理一对句子.输出层解决sentence pair task。
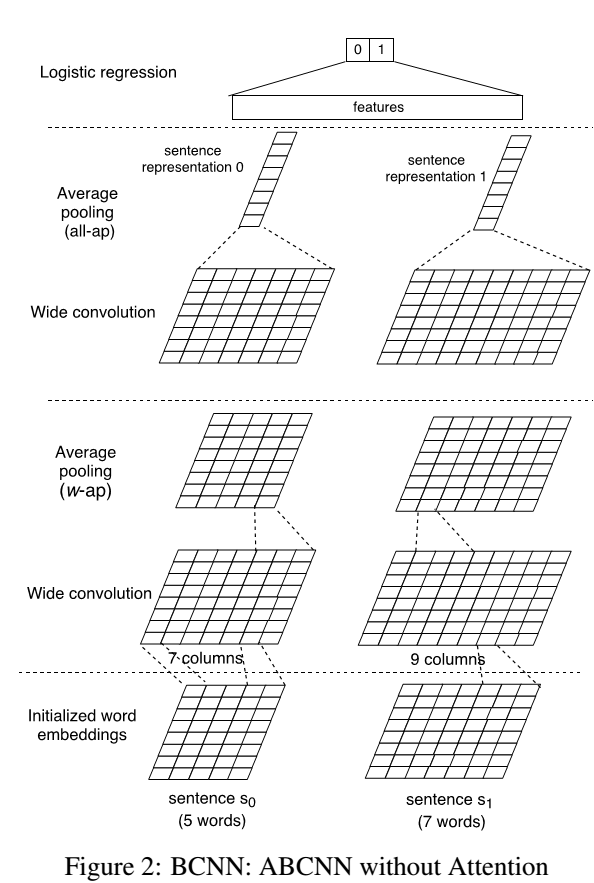
用于对句子对建模,模型中构建了两个并列的CNN层分别对句子进行特征提取,两个层之间共享卷积参数,后续再进行pool等常规操作,最后用一个logistic regression进行分类.
(1)输入层:输入句子长度s分别为5和7,词向量维度为$d_0$,构成两个feature map,大小为$d_0×s$
(2)卷积层:卷积层使用的是宽卷积的方式,边缘处用0进行padding,最后得到s+w-1长度的feature矩阵,如下: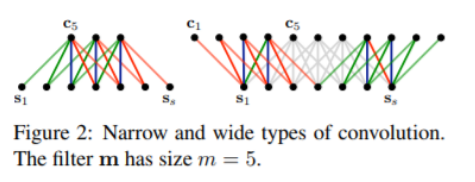
需要注意的是这里并不是per dim卷积的方式,依旧是dim-wise卷积,对于每个卷积核最终生成的都是s+w-1长度的一维向量,之后将多个卷积核生成的结果拼接起来就得到上图的形式.其中W为卷积核,$W∈R^{d_1×wd_0}$,$c_i$为feature map在边缘处padding 0 后根据卷积核大小的切片,$c_i∈R^{w×d_0}$,b为偏置
(3)Average pooling layer:有w-ap与all-ap两种类型.前者用于中间层的池化,对待池化矩阵,定义一个池化窗口大小w,逐个窗口进行池化,最后生成s-w+1长度的feature map,经过卷积与池化操作最终feature map依旧为输入句子的长度s,因此,可以重复进行多次特征提取的操作.all-ap,对于最后一层pooling,采用columns-wise的方式,最终得到一个row长度的一维向量
(4)output layer
最终针对特定任务增加一个层,这里做的是分类任务,所以采用逻辑回归. - ABCNN:Attention-Based BCNN
(1)ABCNN-1: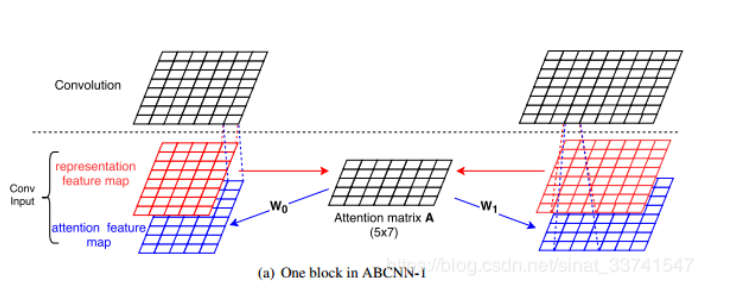
基本想法是在卷积之前,根据两个句子的feature map生成一个Attention matrix A,之后将矩阵A与参数W进行矩阵乘法,构成一个与原始feature map大小一致的新的attention feature map作为卷积输入的另一个通道,之后再进行卷积池化等操作,希望attention feature map能够再卷积操作时起到有关注点的抽取特征,定义attention matrix A∈R^{s×s}如下:其中$match-score=\frac{1}{1+|x-y|}$,|x-y|为欧几里得距离.最后得到的矩阵A为s×s的矩阵,相当于对句子1中的每一个词对句子2中的每一个词求相似度,结果组合成一个矩阵.
根据矩阵A就可以得到attention feature map,其中W为待训练参数
(2)ABCNN-2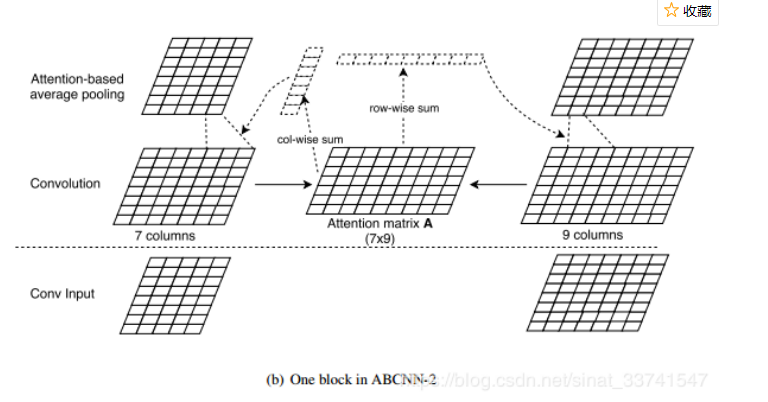
相比于方法1,在卷积前求attention,这里方法是在pooling层前进行attention操作,构造attention matrix A的方式与方法1一致,但是在池化前对卷积的输出进行re-weight,具体的是分别对A进行col-wise sum与row-wise sum,分别得到一个对应的一维向量,即权重,之后再对卷积后的表达重新加权,池化等操作.
相比方法1,方法2的attention更高维度上起作用,在卷积层之前的attention在词级别上起到作用,那进入池化层之前的attention则在短语级别起到作用,短语的长度取决于卷积的大小.同时方法2相对于方法1来说计算量小了,没有参数W,在对抗过拟合方面会更强壮.
(3)ABCNN-3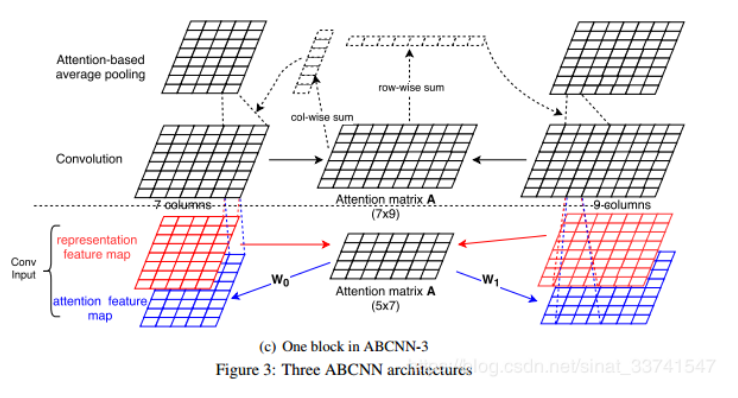
结合方法1和方法2的优点,作者提出方法3,将两个模型融合了起来.
Attention is all you need(Transformer)
之前提到的attention 往往是利用rnn,这会有难以并行的问题.为了解决无法并行训练的问题,google提出了self-attention,完全摒弃了RNN单元,从而做到并行训练.之前Facebook提出的《Convolutional Sequence to Sequence Learning》实现的是cnn替代rnn单元来实现并行.google提出self-attention来代替rnn也算是对facebook的一种回应.
传统的attention-based MT
基本公式如下:
传统的attention-based MT是以RNN单元为前提的,现考虑也换成将RNN也换成attention
attention概念和分类
google先形式化地提出attention的概念.它把attention的三个重要组件分别称为key,value和query.在传统的attention-based MT中,query是解码器的隐状态s,key和value都是编码器的隐状态h.字面上来说,query是查询,主要用于查找编码器隐状态与解码器隐状态的相似度.key是键,即query要比较的值,value是值,一个key对应一个value,query与key的相似度为a,将其作用于value.
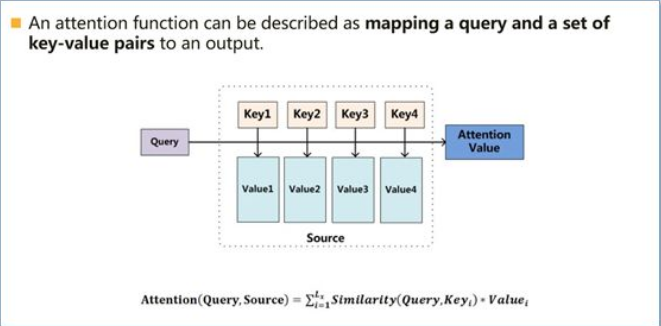
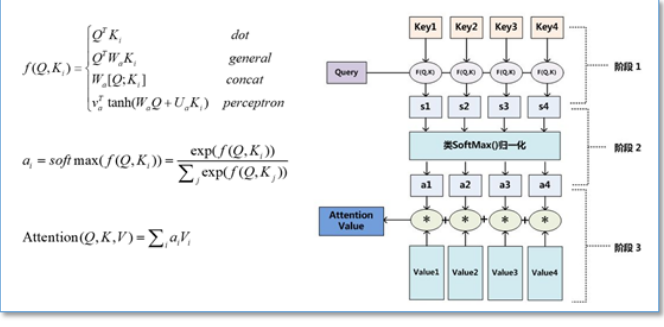
论文中也对attention进行了分类,query来自解码层,key和value来自编码层时叫vanilla attention,即最基本的attention.query,key和value来自编码层的叫self attention
于是很自然,把rnn换成self-attention
- 在编码层,输入的word-embedding就是key,value和query,然后做self-attention得到编码层的输出.
- 然后模拟解码层,解码层的关键是如何得到s,即用来和编码层attention的query,作者发现s与上个位置的真实标签 y,和当前位置的attention输出c有关,换句话说,位置i的s利用了所有它之前的真实label y信息,和所有它之前位置的attention的输出c信息.label y我们是全部已知的,而之前位置c信息虽然也可以利用,但我们不能用,因为那样就不会导致并行.因为在计算当前位置的c需要利用之前位置的c.于是我们只能用真实标签y来模拟解码层的RNN.前面说过,当前位置s使用了它之前的所有真实标签y信息.于是哦我们做一个masked attention,即真实标签 y像编码器x一样做self-attention,但每个位置的y只与它之前的y有关(mask),这样self-attention之后每个位置输出综合了当前位置和他之前的所有y信息,即可做s(query)。
- 得到编码层的key和value以及解码层的query后,下面就是模仿vanilla attention,利用key和value以及query再做最后一个attention.得到每个位置的输出.
总结:x做self-attention得到key和value,y做masked self-attention得到query,然后key,value,query做vanilla-attention得到最终输出.
细节
position embedding(提供位置信息)
论文采用self-attention的一个缺点就是无法使用word的位置信息.RNN可以使用位置信息,因为当位置变化时RNN的输出就会改变.而self-attention各个位置可以说是相互独立的,输出只是各个位置的信息加权输出,并没有考虑各个位置的位置信息.CNN也有类似位置无关的特点.以往的position embedding往往采用类似word embedding式可以随网络训练的位置参数,google提出了一种固定的pe算法:
其中i是相应的维度,如果$d_{model}$=512,那么i的取值就是0-255
即在偶数位置,此word的pe是sin函数,在奇数位置,word的pe是cos函数.论文说明了此pe和传统的训练得到的pe效果接近.并且因为Sin(α+β)=Sin(α)Cos(β)+Cos(α)Sin(β)以及Cos(α+β)=Cos(α)Cos(β)-Sin(α)Sin(β),位置p+k可以用位置p的向量的线性变换表示,也说明此pe不仅可以表示绝对位置,也可以表示相对位置.最后的embedding为word_embedding+position_embedding.而Facebook的论文是拼接了两个embedding.
multi-head attention
有了embedding,接下来就是attention,论文采用了多个attention.首先embedding做h次linear projection,每个linear projection的参数不一样,然后做h次attention,最后把h次attention的结果拼接为最后的输出.作者表明,多个attention便于模型学习不同子空间位置的特征,最终组合起来这些特征,而单头attention直接把这些特征平均,就减少了一些特征的表示可能,如下图: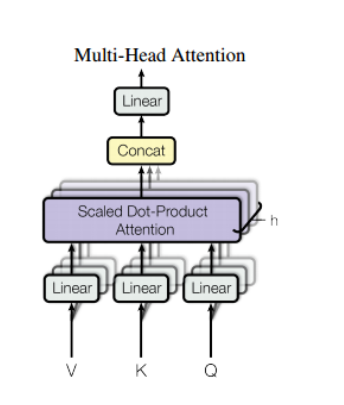
(这里的组合操作是为了更鲁棒)
公式:
其中$head_i=Attention(QW_i^Q,KW_i^K,VW_i^V)$
可以看到,Encoder中有一个multi-head attention,decoder 有两个multi-head attention.Decoder的一级multi-head attention是masked,只会关注已经预测好的结果的注意而不会对未来有注意,接收的是来自上一层的输入,query,key和Value来自上一层,而二级multi-head attention 接收的query来自一级multi-head attention而key和value来自encoder的multi-head attention.
Scaled Dot-Product
这篇论文计算query和key相似度使用了dot-product attention,即query和key进行点乘(内积)来计算相似度
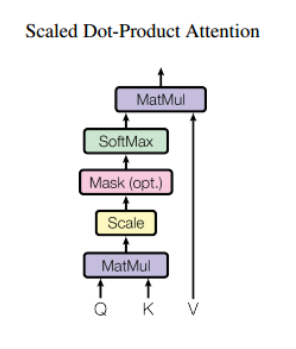
之所以用内积除以维度的开方,论文给出解释是:假设Q和K都是独立的随机变量,满足均值为0,方差为1,则点乘后结果均值为0,方差为$d-k$.方差会随着维度$d_k$增大而增大,而大的方差会导致极小的梯度(主要因为大方差导致有的输出单元a(a是softmax的一个输出)很小,softmax反向传播梯度就很小).为了避免这种大方差带来的训练问题,论文中用内积除以维度的开方,使之变为均值0,方差1.
(避免点乘后值太大,影响softmax回传.)
预测
训练的时候我们知道全部的真实标签,但是预测时是不知道的.可以首先设置一个开始符s,然后把其他label的位置设为pad,然后对这个序列y做masked attention,因为其他位置设为了pad,所以attention只会用到第一个开始符s,然后用masked attention的第一个输出做为query和编码层的输出做普通attention,得到第一个预测的label y,然后把预测的label加入到初始序列y中相应的位置,然后再做masked attention,这时第二个位置就不再是pad,那么attention层就会用到第二个位置的信息,如此循环,最后得到所有的预测label y.其实这样做也就是模拟传统attention的解码层.
Other
label Smoothing
用softmax分类并使用交叉熵函数作为损失函数时,真实标签只有0或1,根据反向求导公式可知,这会难于泛化,并且上层导数容易为0.所以把真实标签smooth,使之成为0-1之间的一个数,而不是两个极端.layer normlization
为了加速训练,避免陷入局部最优stack layers
编码器和解码器都重复N次,最后把结果拼接restricted self-attention
为了缓解需要两两计算相似性的计算代价,作者又提出了restricted版本的self-attention即每个query只需和它邻近的r个key计算相似性.类似于卷积中的窗口概念.(local attention)
网络结构
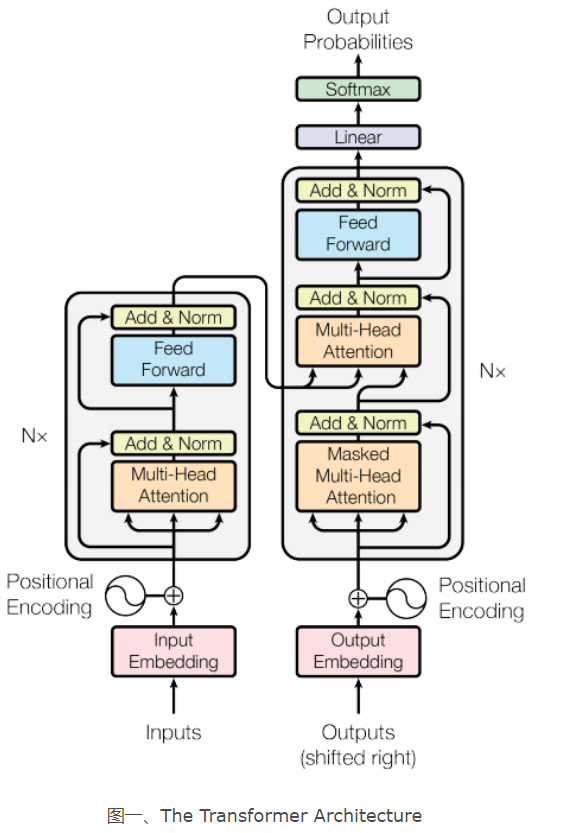
Transformer基本单元
- Add&Norm(AN)单元
Add&Norm=LayerNorm(x+Sublayer(x))
其中Sublayer(x)是前面Multi-Head attention或FeedForward layer的输出
这种连接的两个明显好处:
1)Norm有助于快速训练.LayerNorm是Normalization的变体.简要对比BN与LN:BN是对一个batch的样本数据再单个维度上进行Normalization,LN对一个数据样本的所有维度进行Normalization.LN可以对RNN进行规范化,但BN不行.基于LN的加速比BN快8-10倍.
2)引入Add,尽可能保留原始输入x的信息 Multi-Head Attention
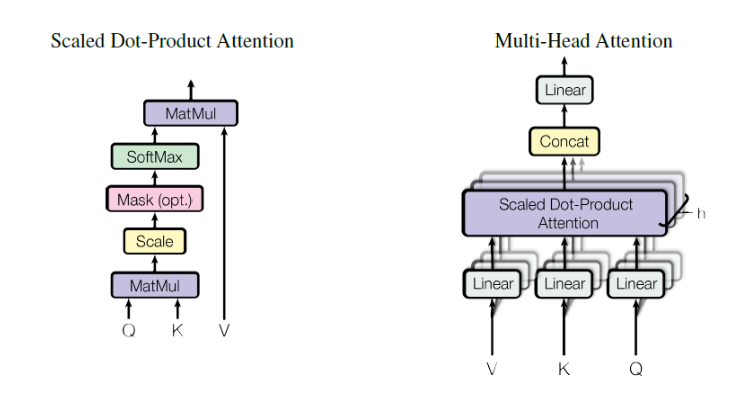
Multi-Head Attention对输入K,V,Q分别进行h次线性变换,然后进行h次Scaled Dot-Product Attention,这类似于卷积网络里使用不同卷积核进行多次卷积操作.Multi-Head Attention可以使模型从不同的角度获取输入X的不同subspaces representation.由于在线性变换时对每个样本的维度做了reduce(变为原来的1/h),这使得Multi-Head Attention总的计算量与Single-Head Attention差不多position-wise(逐项)的feed forward网络
Multi-Head Attention子层后面跟了一个feed-forward Network(简称FFN),它由两个线性变换组成,中间嵌入一个ReLU激活函数,如下:这样做的目的应该是提高模型特征抽取的能力,考虑到效率,选择两个线性变换
position Encoding
传统的方式是用word2vec方式训练,而本文采用较简单方式,基于正弦和余弦函数,根据位置pos和维度i来计算
Encoder端:input embedding与position embedding的加和作为堆叠N(N=6)个完全相同的layer层的输入.每个layer层均由一个self-attention子层和FeedForward子层组成.两个子层直接通过Add&Norm的方式进行连接
Decoder端:output embedding与positional embedding的加和作为堆叠N(N=6)个相同的layer层的输入.该输入作为decoder self-attention子层的输入(Q=K=V).然后self-attention子层的输出作为中间Attention层的输入(Q),同时,encoder中对应于该层(0-N)的输出也作为中间Attention层的输入(K=V).随后,中间Attention层的输出作为decoderFeedForward层的输入.以此类推,所有的layer都这样work.最后通过一个线性变换(Linear)和Softmax,就可以得到目标输出的一个概率分布.
Seq2Seq
一般来说,Seq2Seq模型主要是用来解决一个序列X转换到另一个序列Y的一类问题,此处优点类似隐马尔科夫模型.通过一系列随机变量X,去预测另外一系列随机变量Y.但不同的是隐马尔可夫模型中的随机序列与随机变量系列一一对应,而Seq2Seq模型则并不是一一对应关系.Seq2Seq模型主要应用包括机器翻译,自动摘要等端到端的生成应用.
对于Seq2Seq生成模型来说,主要的思路是将该问题作为条件语言模型,在已知输入序列和前序生成序列的条件下,最大化下一个目标词的概率,而最终希望得到的是整个输出序列的生成出现的概率最大:
说明:
- 在训练时模型会用到$y_{1:t-1}$但是在测试过程中,ground truth 便是不可知的,需要使用前期预测到的$y’_ {1:t-1}$来表示,着就会引发问题Exposure Bias。
采用的trick:使用Beam Search的Encoder的方式能在一定程度上降低Exposure Bias问题,因为它考虑了全局解码概率,而不是仅仅依赖于当前一个词的输出,所以模型前一个预测错误带来的误差传递的可能性会降低.
- 在预测输出序列的每个token时,采用的都是最大化下一目标的概率,来得到token,对于整个句子或者序列来说,这种方法是贪心策略,带来的是局部最佳.对于一个端到端的生成应用来说,将会追求整个序列的最佳,换句话说,希望最后生成序列的tokens顺序排列的联合概率最大,找到全局最优
Seq2Seq模型
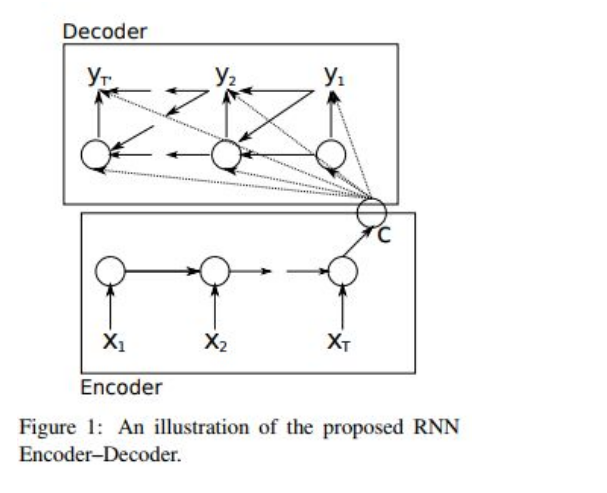
上图可以看出,Encoder使用RNN编码后形成语义向量C,再将语义向量C作为Decoder的输入.解码过程中,每个时间点t的输入就是上一个时刻隐层状态$h_{t-1}$和上一时刻的预测输出$y_{t-1}$和中间语义向量C,输出的是此时刻的隐状态$h_t$.
其中f是非线性激活函数.
随后,通过$h_t$和$y_{t-1}$生成此刻的预测输出$y_t$.
最后Seq2Seq两个部分(Encoder和Decoder)联合训练的目标函数是最大化条件似然函数.其中$\theta$为模型的参数,N为训练集的样本个数.
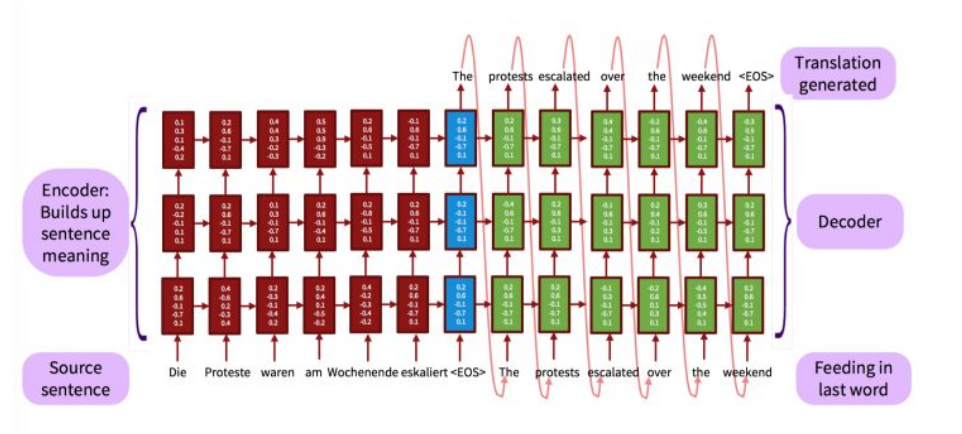
加入attention的Seq2Seq
原来的Seq2Seq的主要问题是Encoder将所有的信息都挤压在一个固定长度的信息向量C中,会导致在Decoder的过程处理某个时间点时源语言提供的信息不充足,从而导致效果不佳.
Seq2Seq的问题及相应解决trick
Sampled Softmax
问题:Seq2Seq模型的代价函数的loss是sampled_softmax_loss。为什么不是softmax_loss?因为对于Seq2Seq的模型来说,输入和输出序列的class便是词汇表的大小,而对于训练集来说,输入和输出的词汇表的大小是比较大的.为了减少计算每个词的softmax的时候的资源压力,通常会减少词汇的带线啊哦,但是便会带来另外一个问题,由于词汇表的词量的减少,语句的Embedding的id表示时容易大频率的出现未登录词“UNK”,于是希望找到一个能使Seq2Seq使用较大词汇表,但又不怎么影响计算效率的解决办法
trick:《On Using Very Larg Target Vocabulary for Neural Machine Translation》论文中提出了计算词汇表的softmax的时候,并不采用全部的词汇表的词,而是进行一定手段的sampled,的采样,从而近似的表示词汇表的loss输出.sampled采样需要定义好候选分布Q.即按照什么分布去采样.Encoder阶段的Beam Search
Seq2Seq模型的最终目的是希望生成的序列发生的概率最大,也就是生成序列的联合概率最大.在实际预测输出序列的每个token的时候,采用的都是最大化下一目标词(token)的概率,因为Decoder的当前时刻的输出是根据前一时刻的输出,上一时刻的隐藏状态和语义向量C,通过依次求每个时刻的条件概率最大来近似获得生成序列的发生最大的概率,这种做法属于贪心思维的做法,获得是局部最优的生成序列.
trick:《Sequence-to-Sequence Learning as Beam-Search Optimization》论文中提出Beam-Search来优化上述的局部最优化问题.Beam-Search属于全局解码算法.Encoder解码的目的是要得到到生成序列的概率最大,可以把它看作是图上的一个最优路径问题。