金融壹帐通Gamma Lab CV实习生面经
resnet是为了解决什么样的问题
一直以为resnet解决的是梯度弥散或是梯度爆炸的问题,但查了这个问题才发现并不是这样的.Kaiming的论文中已经说了臭名昭著的梯度弥散/爆炸问题已经很大程度上被normalized initialization and intermediate normalization layer解决了。图像由于具有局部相关性,因此认为梯度也应该具备相关性,但是在梯度更新期间,梯度的相关性会随着层数的变深而呈指数性衰减,导致梯度趋近于白噪声,而skip-connections可以缓解衰减速度,使相关性和之前比起来更大。(尽管我还是觉得跟梯度消失和爆照有关,望有人能解答)残差指的是什么?
ResNet提出了两种map:一种是identity mapping,另一种是residual mapping.y=F(x)+x,F(x)就是哪个残差densenet 和resnet的不同之处?
resnet的公式:即第l层的输出等于l-1层的输出加上对l-1层输出的非线性变换
DenseNet的公式:其中方括号[]表示拼接,也就是说[x_0,x_1,…,x_{l-1}]代表对第0~L-1层的特征图进行拼接。$H_l(·)$表示复合函数.
在小数据的时候,因为小数据时容易产生过拟合,但是densenet能很好地解决过拟合问题,所以对于小数据集的情况下,densenet的效果要好于resnet:因为DenseNet具有非常好的抗过拟合性能,尤其适合训练数据相对匮乏的应用.比较直观的解释:神经网络每一层提取的特征都相当于对输入数据的一个非线性变换,而随着深度的增加,变换的复杂度也逐渐增加(更多非线性函数的复合).相比于一般神经网络的分类器直接依赖于网络最后一层(复杂度最高的特征),DenseNet可以综合利用浅层复杂度低的特征,因而更容易得到一个光滑的具有更好泛化性能的决策函数.- SVM原理
考虑两类问题,SVM就是找到能最大分割这两类的超平面. - relu负半轴出现饱和为什么好要用它
???? - 一个定位问题(目标检测),你如何评价这个模型的好坏?
用Mean Average Precision(mAP).为什么要用mAP,因为每张图可能包含多个类别的多个目标,因此,目标检测模型的评价需要同时评价模型的定位、分类效果
对于目标检测问题而言,ground truth包括”image”、”classes of the objects” 以及”true bounding boxes of each of the objects in that image”
一张图里假设有狗、人、马三个标记,我们需要1.类别标签2.x,y坐标标签3.宽高标签
这是一个都分类的问题,往往会涉及到找回率(recall)和精确率(precision)的问题:
$Recall =\frac{TP}{TP+FN}$,
$Precision=\frac{TP}{TP+FP}$
在多分类中,如果仅仅是把groud truth的类当作正例,其他类当作负例,好像优点类表达的不够充分.因此考虑从分类的置信度(某个类的)中进行排序,由高到底排列可以用topN来作为一个阈值,前N个表示正样例,而后面的表示负样例.由此我们就可以得到TP、FN、FP.并且可以由此得到P-R曲线.有了PR曲线,我们可以求AP,什么是AP,AP就是通过改变上述阈值求得的P-R曲线面积们的平均值.由此AP衡量出了学出的模型在给定类别上的好坏,而mAP衡量的是学出的模型在所有类别上的好坏,即对各个类的AP求平均值.(注意:有时也不用TopN而是用一个置信度阈值,大于该阈值时为positive.) - 为什么引入ReLu激活函数
引入非线性激活函数是因为,如果不用非线性激活函数,多层线性函数只相当于一层.
之所以是ReLu而不是其他的比如sigmoid是因为sigmoid的计算量大,且在反向传播的过程中两端的饱和区梯度趋近于0.而ReLu尽管一侧饱和区输出的都是0,但是这样造成了一定的网络洗属性,减少了参数的相互依存关系,缓解了过拟合的发生
平安科技医疗部计算机视觉算法电面一面面经
类别不平衡如何解决
数据层面
ResNet的特点:
跳跃连接和瓶颈层
为什么要用1×1的卷积
1×1的卷积来源于Network in Network
主要作用使:
- 降维,提高泛化能力,防止过拟合
- 减少参数
- 在保持feature map尺度不变的前提下大幅增加非线性特性,把网络做的deep
- 实现跨通道的信息交互和整合
知道哪些机器学习常用的损失函数?
- 交叉熵损失
- hinge loss
- L1损失
- L2损失
- Focal loss
什么是Focal loss
Focal loss主要是为了解决one-stage目标检测中正负样本比例严重失衡的问题。该函数降低了大量简单负样本在训练中所占的权重,也可以理解为一种困难样本挖掘
原来的二分类的交叉熵形式为:其中y’是经过激活函数的输出,在0-1之间.对预测为正例的概率。
Focal loss将其改写为:L1和L2损失在目标检测中的应用知道吗
L2损失对异常点比较敏感,因为L2将误差平方化,使异常点的误差增大.
L1损失函数由于导数不连续,可能存在多个解,当数据解有一个微小的改变,解也有可能有很大改动.具有不稳定的问题.
smoothL1损失函数其中smoothL1损失函数是在Faster RCNN中出现的,它可以让离群点更加鲁棒(相比于L2),且相比于L1更加稳定。小米机器学习算法工程师面经
bagging和boosting的区别
- 样本上
Bagging:追求的是小方差,要每个模型覆盖的方差不同,因此训练集是在原始集中有放回的选取,且从原始集中选出的各轮训练集之间是独立的
Boosting:追求的是小误差,每一轮的训练集不变,只是训练集集中每个样例在分类其中的权重发生变化。权重与上一轮分类结果有关 - 样例权重上
Bagging:使用均匀采样,每个样例权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大权重越大 - 计算方式:
Bagging:并行计算
Boosting:串行计算为什么说Bagging减少variance,而boosting是减少bias
- Bagging对样本重采样,对每一重采样得到的子样本集训练一个模型,最后取平均.一般我们都假设各个模型有近似的bias和variance.显然由于$E[\frac{\sum X_i}{n}]=E[X_i]$,可以看出,bagging后的偏差与单个模型差不多,但是对于方差,则有$Var(\frac{\sum X_i}{n})=\frac{Var(X_i)}{n}$,显著降低了variance
- 而boosting是每次作用在相同的样本集,不断地增加错误样本的权重以缩小残差.通过用新的模型拟合残差,来逐步降低bias.
手推逻辑回归
逻辑回归是个分类问题,在线性回归的基础上增加了一个sigmoid函数,使其值域落在[0,1]之间,可以表征分类的概率其中z=wx最简单的构建方法是极大似然估计梯度上升法迭代求参其中$\phi’(z)=\phi(z)(1-\phi(z))$
得到:梯度消失的解决办法
为什么会产生梯度消失或爆炸:
因为在反向传播的过程中,梯度回传的方式是连乘形式,所以深度一增加就容易出现爆炸和消失的问题 - 预训练+微调
- 梯度截断、权重正则(针对梯度爆炸)
- BatchNorm
- 残差结构
- 使用LSTM(序列模型)
- 改变不同的激活函数,像sigmoid就有会有饱和区,而relu就不存在梯度消失爆炸的问题
BatchNorm是如何缓解梯度消失的
BatchNorm主要解决的是Internal Covariate Shift(内部协变量转移)的问题.
Internal Covariate Shift的概念:
首先是来自于机器学习中
BatchNorm对每一层中的输入信号保证其稳定,将会消除带来的放大缩小的影响,进而解决梯度消失和爆炸的问题,或者可以理解为BN将输入数据(输出数据,该层的输出是下一层的输入)从饱和区拉到非饱和区.
BatchNorm的其他好处:
- 极大提升了训练速度,收敛过程大大加快
- 类似于Dropout的一种防止过拟合的正则化表达方式
聚类有哪几种?
- 基于划分的(k-means):其思想是类内点足够近类外点足够远,通过一种启发式算法实现
- 基于层次的:(有自底向上的凝聚方法例AGNES和自上向下的分裂方法,例DIANA):两个cluster之间的距离可以有以下取法:1. 最小距离 2.最大距离 3.平均距离,然后以树的形式分裂或合并.
- 基于密度的(DBSCAN)
L1和L2正则化的方法
L1 regularizer 和L2 regularizer都是可以用于避免过拟合
L1 regularizer:优良性质是能产生稀疏性,产生稀疏权重矩阵.L1适用于特征之间有关联的情况。
L2 regularizer:让所有的特征系数都缩小,但是不会减为0,他会使优化求解稳定快速.所以L2适用于特征之间没有关联的情况.
通过图来分析: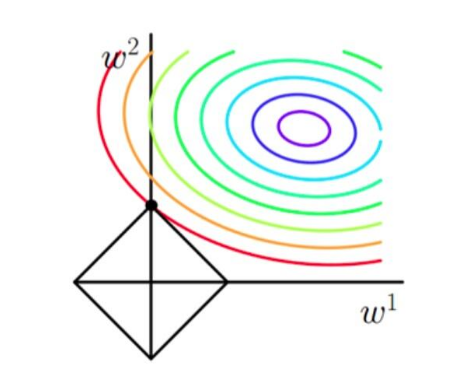
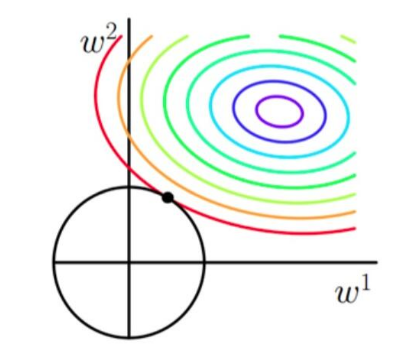
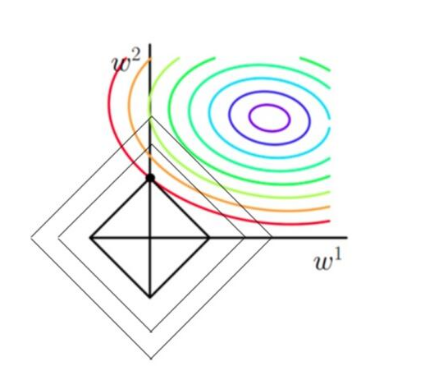
从上图L1可以看到,彩色的等高线表示同一个loss,当L1最小的时候,整个L最小,而从图上可以看到,L在靠近w2轴的地方更容易找到最小值.所以L1有稀疏性.
大佬春招实习算法面经
bn原理以及改进
在ML中为了加速训练往往首先会对数据进行预处理,常用的是零均值和PCA(白化).训练开始前,对数据进行零均值是一个必要的操作.但是,随着网络层次加深参数对分布的影响不定,导致网络每层间以及不同迭代的相同层次的输入分布发生改变,导致网络需要重新适应新的分布,迫使我们降低学习率减少影响.这个背景下BN算法开始出现.但是有些人首先提出在每层增加PCA白化(先对数据去相关然后再进行归一化),这样基本满足了数据的零均值、单位方差、弱相关性。但是这样是不可取的,因为再白化过程中涉及计算协方差矩阵、求逆等操作,计算量会很大,另外在反向传播时,白化也不一定可微,因此出现了BN算法。
白化:PCA白化和ZCA白化
PCA白化保证数据各维度的方差为1,而ZCA白化保证数据各维度的方差相同.PCA白化可以用于降维也可以去相关性,而ZCA白化主要用于去相关性,且尽量使白化后的数据接近原始输入数据.
- PCA白化
根据白化的两个要求:首先我们是降低特征之间的相关性,在PCA中,我们选取前K大的特征值的特征向量作为投影方向.如果K<n,其中n是数据的维度,则还有降维的效果.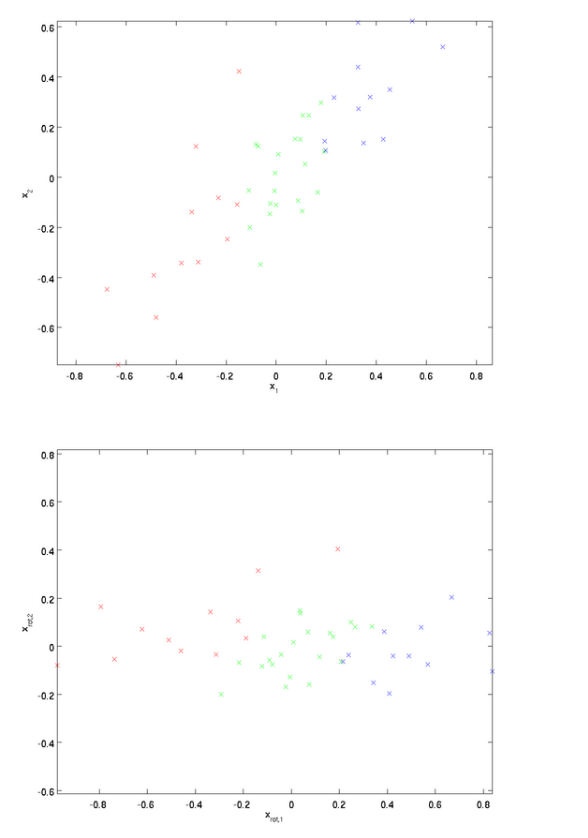
上图为原数据在二维坐标下的分布,下图为原数据经过坐标变换后的二维坐标下的分布.从原数据中可以看出,x1增加,x2也增加,两者相关性为正.而从变换后的图中可以看到这种相关性明显降低了。
其次的一个要求是每个输入特征具有单位方差,以直接使用$1/\sqrt{\lambda_i}$作为缩放因子来缩放每个特征$x_{rot,i}$,经过PCA白化处理的数据分布如下图所示,此时协方差矩阵为单位阵I.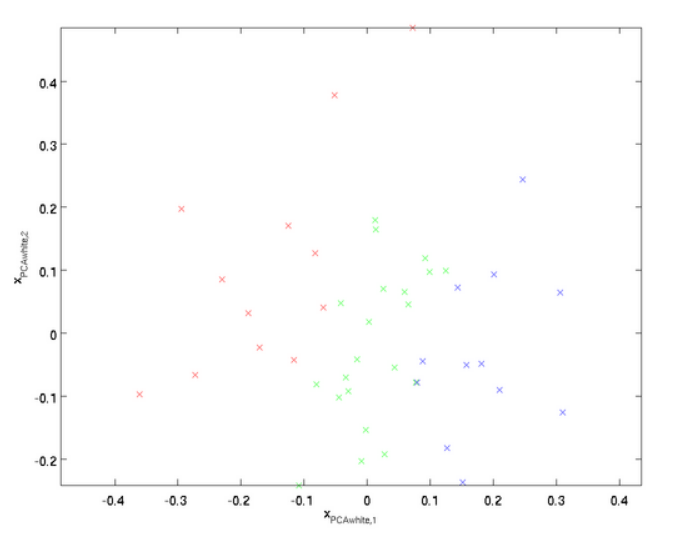
- ZCA白化的定义为:ZCA白化只是在PCA白化的基础上做了一个旋转操作,使得白化之后的数据更加接近真实数据.
ZCA白化首先通过PCA去除了各个特征之间的相关性,然后是输入特征具有单位方差,此时得到PCA白化后的处理结果,然后再把数据旋转回去,得到ZCA白化的处理结果,感觉这个过程让数据的特征之间又具有了一定的相关性. - PCA白化和ZCA白化的区别
PCA白化ZCA白化都降低了特征之间的相关性,同时使得所有特征具有相通的方差
- PCA白化需要保证数据各维度的方差为1,ZCA白化只需保证方差相等
- PCA白化可以进行降维也可以去相关性,而ZCA白化主要用于去相关性.
- ZCA白化相比于PCA白化使得处理后的数据更加接近原始数据
BN算法的产生
上面提到了PCA白化的优点,能够去相关性和数据均值,标准归一化等优点.因此采用一下近似的白化预处理(没有PCA)
由于训练过程采用了batch随机梯度下降,因此E[x^{(k)}]指的是一批训练数据时,各神经元输入值的平均值;$\sqrt{Var[x^{(k)}]}$指的是一批训练数据时各神经元输入值得标准差.
但是,这些应用到深度学习网络中远远不够,因为可能由于这种强制转化导致数据的分布发生破坏.因此需要对公式的鲁棒性进行优化,就有人提出了变换重构的概念.
这里的参数$\gammma^{(k)}和β^{(k)}$都是可训练的.
BN的改进见深度学习中各种Normalization
Dropout原理
Dropout出现的原因,模型的参数太多,而训练样本又太少,训练出来的模型很容易过拟合的现象.在训练神经网络的时候疆场会遇到过拟合的问题.过拟合具体表现在:模型在训练数据上损失函数较小,预测准确率较高;但是在测试数据上损失函数比较大,预测准确率较低.
原理:减少中间特征的数量,同时可以从ensemble的角度考虑,随机丢弃的几个神经元,相当于一个不同的模型,而在测试的时候取平均相当于进行ensemble的过程.
Dropout的一种变体是Dropconnect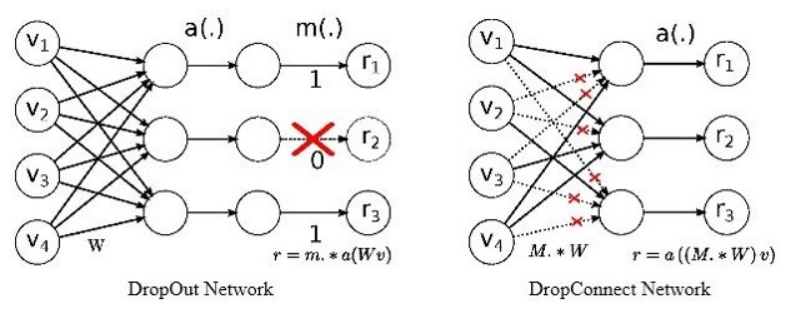
两者的区别很明显:
Dropout是对输出进行随机置零,而Dropconnect是对权重进行随机置零.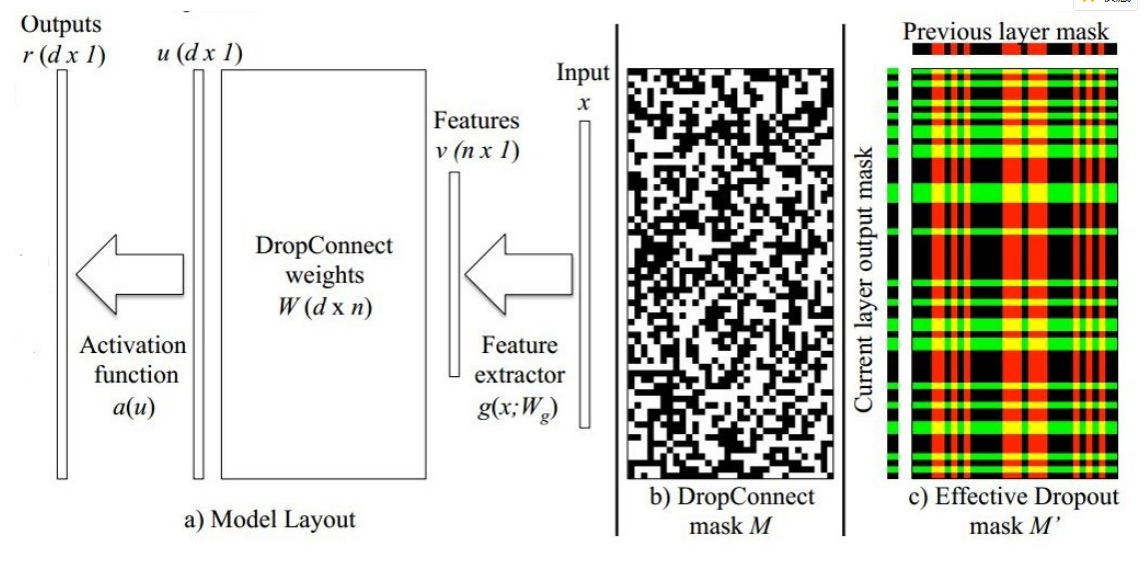
Dropconnect 训练时:与Dropout基本相同
Dropconnect 测试时:wine吧需要一种近似的方法
r=a((M.×W)v)
$r_i=a(u_i)$
$u_i=\sum_j(W_{ij}v_j)M_{ij} ~ N(\mu,\sigma^2)$
$\mu=pWv \sigma=p(1-p)(W×W)(v×v)$
假设M的维度为m×n,则可能的掩膜有$2^{m×n}种$,这时可以用中心极限定理:和分布渐进正态分布,来求得最终的近似结果.
具体流程:
其中Z是在正态分布上的采样次数,一般来说越大越好,但会使计算变慢.
空洞卷积与感受野
空洞卷积是为了解决基于FCN思想的语义分割中,输出图像的size要求和输入图像的size一致而需要upsample,但由于FCN中使用pooling操作来增大感受野同时降低分辨率,导致upsample 无法还原由于pooling导致的一些细节信息的损失问题而提出的.为了减小这种损失,自然需要移除pooling层,因此空洞卷积应运而生.
所谓空洞卷积,一种理解就是在卷积核中注入空洞(即0),注入的空洞的数量由参数dilation决定,以3×3卷积核为例,dilation=2即在卷积核每行每列中间加0,将卷积核变为5×5.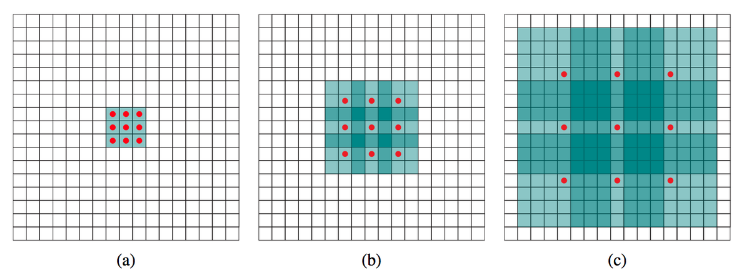
(a)普通卷积,1-dilated convolution,卷积核的感受野为3×3
(b)扩张卷积,2-dilated convolution,卷积核的感受野为7×7
(c)扩张卷积,4-dilated convolution,卷积核的感受野为15×15
由上可知n-dilated convolution的膨胀卷积核大小为:
- IN:输入feature map
- OUT:输出 feature map
- FILTER:卷积核的尺寸
- PADDING:补0
- STRIDE:步长
CNN感受野的计算
其中r为本层感受野,m为上层感受野,stride为卷积或池化的步长.ksize为卷积核的大小
空洞卷积的作用:
- 扩大感受野:
- 捕获多尺度上下文信息:设置不同的dilation rate时,感受野就会不一样,也即获取多尺度信息.多尺度信息在视觉任务钟非常重要.
语义分割由于需要获得较大的分辨率图,因此常在网络的最后两个stage,取消降采样操作,之后采用空洞卷积弥补丢失的感受野
空洞卷积gridding问题:
空洞卷积存在理论问题,其实就是网格效应/棋盘问题.因为空洞卷积得到的某一层的结果中,邻近的像素是从相互独立的子集中卷积得到,相互之间缺少依赖
- 局部信息丢失:由于空洞卷积的计算方式类似于棋盘格式,某一层得到的卷积结果,来自上一层的独立的集合,没有相互依赖,因此该层的卷积结果之间没有相关性,即局部信息缺失
- 远距离获取的信息没有相关性:由于空洞卷积稀疏的采样输入信号,使得远距离卷积得到的信息之间没有相关性,影响分类结果.
解决方案:
- Panqu Wang,Pengfei Chen, et al.Understanding Convolution for Semantic Segmentation.//WACV 2018
- Sachin Mehta,et al. ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation. //ECCV 2018
- Hyojin Park,et al.Concentrated-Comprehensive Convolutions for lightweight semantic segmentation.//2018
为什么MaskRCNN要解耦
MaskRCNN将任务分解,目标检测、定位与分割依次逐一进行,前者决定了后者的输入,因此称任务解耦和.而FCN则将三类任务在一个网络中同时进行,不分现后,任务高度耦合.
一些常见的工程性问题
LR+离散特征
在工业界,很少直接将连续值作为特征喂给逻辑回归模型,而是将连续特征离散化为一系列0、1特征交给逻辑回归模型,这样做的优势有以下几点:
- 稀疏向量内积乘法运算速度快,计算结果方便存储,容易scalable(扩展).
- 离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0.如果特征没有离散化,一个异常数据“300岁”会给模型造成很大的干扰.
- 逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合.
- 离散化后可以进行特征交叉,由M+N各变量变为M×N个变量,进一步引入非线性,提升表达能力
- 特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间不会因为以恶搞用户年龄长了一岁就完全不同.但处于区间相邻处的样本会刚好相反,所以怎么划分区间是个学问.
LR+离散特征原因
深度学习一般而言会学出一个dense reoresentation,而特征工程做出来的是一堆sparse representation.某些时候,人工特征其实跟神经网络经过几层非线性之后的结果是高度相似的.在暴力提取高阶/非线性特征的本事上,及其肯定胜过人类.但有些时候,人工features会outperform暴力的机器方法.所以,特征离散化,从数学角度来可以认为是增加robustness.
LR适用于稀疏特征原因
对于高维稀疏特征,GBDT很容易过拟合.现在的模型普遍都会带着正则项,而LR等线性模型的正则项是对权重惩罚,而树模型的惩罚项通常为叶子结点数和深度等,如果一个例子10个样本都是类别1,而特征f1的值为0,1,而恰好这10个样本的f1特征值都为1,其余9990个样本的特征f1为0.此时树只需要一个结点就能完全分割9990和10个样本,惩罚项及其之小.
为什么LR只适合离散特征
注意离散和连续的最大区别是,对一个字段做连续化的结果就还只是一个特征,而离散化后这一列有多少个key(字段可能的值)就会抽取出多少个特征.
- 单变量离散化为N个后,每个变量有单独的权重,在激活函数的作用下相当于为模型增加了非线性,能够提升模型的表达能力,加大拟合.
- 离散化后的特征对异常数据有很强的鲁棒性
- 离散特征的增加和减少都很容易,易于模型的快速迭代.
- 有些人会担心特征多运算缓慢,但是LR是线性模型,在内部计算的时候是向量化计算,而不是循环迭代.
海量离散特征+LR是业内常见的一个做法,而少量连续特征+复杂模型是另外一种做法.
字节跳动计算机视觉算法实习生视频面试(45个问答)
focal loss
$y=1时 -(1-y’)^\gamma logy’$
$y=0时 -y’^{\gamma}log(1-y)$
此外还会加入一个平衡因子α来平衡正负样本本身的比例不均
$y=1时 -α(1-y’)^\gamma logy’$
$y=0时 -(1-α)y’^\gamma log(1-y’)$