GBDT算法流程
GBDT通过采用加法模型(基函数的线性组合),以及不断减少训练过程产生的残差来达到将数据分类或回归的算法.(boosting的过程)
训练过程: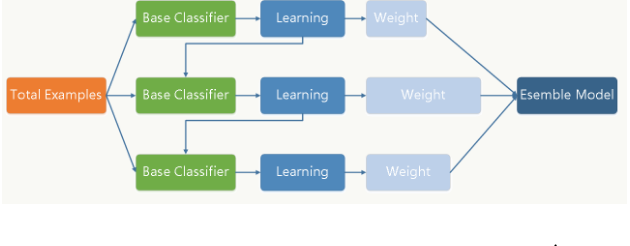
gbdt通过多轮迭代,每轮迭代产生一个弱分类器,每个分类器在上一轮分类器的残差基础上进行训练。对弱分类器的要求一般是足够简单,并且是低方差和高偏差的。因为训练的过程是通过降低偏差来不断提高最终分类器的精度,(此处是可以证明的)。
弱分类器一般会选择为CART TREE(也就是分类回归树)。由于上述高偏差和简单的要求 每个分类回归树的深度不会很深。最终的总分类器 是将每轮训练得到的弱分类器加权求和得到的(也就是加法模型)。
模型最终可以描述为:
模型一共训练M轮,每轮产生一个弱分类器$T(x;\theta)$.弱分类器的损失函数
这边采用的是经验风险最小化来确定下一个弱分类器的参数.具体到损失函数本身的选择也就是L的选择,有平方损失函数,0-1损失函数,对数损失函数等等.如果我们许纳泽平方损失函数,那么这个差值其实就是残差.
让损失函数沿着梯度的方向下降,这就是GBDT的GB的核心.用一个回归树来拟合残差。GBDT每轮迭代的时候都会去拟合损失函数在当前模型下的负梯度。这样每轮训练的时候能够让损失函数尽可能快的减小,尽快的收敛达到局部最优解或者全局最优解.
注意:GBDT的是在GB上面,采用了负梯度作为残差的概念

GBDT如何选择特征
gbdt的弱分类器默认选择的是CART TREE。其实也可以选择其他弱分类器的,选择的前提是低方差和高偏差。框架服从boosting 框架即可。
下面我们具体来说CART TREE(是一种二叉树) 如何生成。CART TREE 生成的过程其实就是一个选择特征的过程。假设我们目前总共有 M 个特征。第一步我们需要从中选择出一个特征 j,做为二叉树的第一个节点。然后对特征 j 的值选择一个切分点 m. 一个 样本的特征j的值 如果小于m,则分为一类,如果大于m,则分为另外一类。如此便构建了CART 树的一个节点。其他节点的生成过程和这个是一样的。现在的问题是在每轮迭代的时候,如何选择这个特征 j,以及如何选择特征 j 的切分点 m:
- 原始的gbdt的做法非常的暴力,首先遍历每个特征,然后对每个特征遍历它所有可能的切分点,找到最优特征 m 的最优切分点 j。
- 如何衡量我们找到的特征 m和切分点 j 是最优的呢? 我们用定义一个函数 FindLossAndSplit 来展示一下求解过程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37def findLossAndSplit(x,y):
# 我们用 x 来表示训练数据
# 我们用 y 来表示训练数据的label
# x[i]表示训练数据的第i个特征
# x_i 表示第i个训练样本
# minLoss 表示最小的损失
minLoss = Integet.max_value
# feature 表示是训练的数据第几纬度的特征
feature = 0
# split 表示切分点的个数
split = 0
# M 表示 样本x的特征个数
for j in range(0,M):
# 该维特征下,特征值的每个切分点,这里具体的切分方式可以自己定义
for c in range(0,x[j]):
L = 0
# 第一类
R1 = {x|x[j] <= c}
# 第二类
R2 = {x|x[j] > c}
# 属于第一类样本的y值的平均值
y1 = ave{y|x 属于 R1}
# 属于第二类样本的y值的平均值
y2 = ave{y| x 属于 R2}
# 遍历所有的样本,找到 loss funtion 的值
for x_1 in all x
if x_1 属于 R1:
L += (y_1 - y1)^2
else:
L += (y_1 - y2)^2
if L < minLoss:
minLoss = L
feature = i
split = c
return minLoss,feature ,split
这里的目标函数是下式:
GBDT如何构建特征?
其实说gbdt 能够构建特征并非很准确,gbdt 本身是不能产生特征的,但是我们可以利用gbdt去产生特征的组合。在CTR预估中,工业界一般会采用逻辑回归去进行处理,逻辑回归本身是适合处理线性可分的数据,如果我们想让逻辑回归处理非线性的数据,其中一种方式便是组合不同特征,增强逻辑回归对非线性分布的拟合能力。
长久以来,我们都是通过人工的先验知识或者实验来获得有效的组合特征,但是很多时候,使用人工经验知识来组合特征过于耗费人力,造成了机器学习当中一个很奇特的现象:有多少人工就有多少智能。关键是这样通过人工去组合特征并不一定能够提升模型的效果。所以我们的从业者或者学界一直都有一个趋势便是通过算法自动,高效的寻找到有效的特征组合。Facebook 在2014年 发表的一篇论文便是这种尝试下的产物,利用gbdt去产生有效的特征组合,以便用于逻辑回归的训练,提升模型最终的效果。
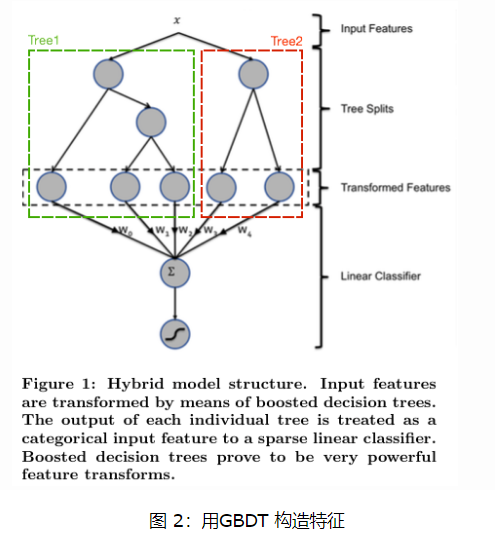
如图 2所示,我们 使用 GBDT 生成了两棵树,两颗树一共有五个叶子节点。我们将样本 X 输入到两颗树当中去,样本X 落在了第一棵树的第二个叶子节点,第二颗树的第一个叶子节点,于是我们便可以依次构建一个五纬的特征向量,每一个纬度代表了一个叶子节点,样本落在这个叶子节点上面的话那么值为1,没有落在该叶子节点的话,那么值为 0.
于是对于该样本,我们可以得到一个向量[0,1,0,1,0] 作为该样本的组合特征,和原来的特征一起输入到逻辑回归当中进行训练。实验证明这样会得到比较显著的效果提升。
GBDT如何用于分类
首先明确一点,gbdt 无论用于分类还是回归一直都是使用的CART 回归树。不会因为我们所选择的任务是分类任务就选用分类树,这里面的核心是因为gbdt 每轮的训练是在上一轮的训练的残差基础之上进行训练的。这里的残差就是当前模型的负梯度值 。这个要求每轮迭代的时候,弱分类器的输出的结果相减是有意义的。残差相减是有意义的。
如果选用的弱分类器是分类树,类别相减是没有意义的。上一轮输出的是样本 x 属于 A类,本一轮训练输出的是样本 x 属于 B类。 A 和 B 很多时候甚至都没有比较的意义,A 类- B类是没有意义的。
- 我们在训练的时候,是针对样本 X 每个可能的类都训练一个分类回归树。举例说明,目前样本有三类,也就是 K = 3。样本 x 属于 第二类。那么针对该样本 x 的分类结果,其实我们可以用一个 三维向量 [0,1,0] 来表示。0表示样本不属于该类,1表示样本属于该类。由于样本已经属于第二类了,所以第二类对应的向量维度为1,其他位置为0。针对样本有 三类的情况,我们实质上是在每轮的训练的时候是同时训练三颗树。第一颗树针对样本x的第一类,输入为(x,0)(x,0)。第二颗树输入针对 样本x 的第二类,输入为(x,1)(x,1)。第三颗树针对样本x 的第三类,输入为(x,0)
- 在这里每颗树的训练过程其实就是就是我们之前已经提到过的CATR TREE 的生成过程。在此处我们参照之前的生成树的程序 即可以就解出三颗树,以及三颗树对x 类别的预测值f1(x),f2(x),f3(x)f1(x),f2(x),f3(x)。那么在此类训练中,我们仿照多分类的逻辑回归 ,使用softmax 来产生概率,则属于类别 1 的概率
- 并且我们我们可以针对类别1 求出 残差y_{11}(x)=0−p_1(x);类别2 求出残差y_{22}(x)=1−p_2(x);类别3 求出残差y_{33}(x)=0−p_3(x).
然后开始第二轮训练 针对第一类 输入为(x,y_{11}(x)), 针对第二类输入为(x,y_{22}(x)), 针对 第三类输入为 (x,y_{33}(x)).继续训练出三颗树。一直迭代M轮。每轮构建 3颗树.所以当K =3。我们其实应该有三个式子其中m表示训练的轮数
当训练完毕以后,新来一个样本 x_1 ,我们需要预测该样本的类别的时候,便可以有这三个式子产生三个值,f_1(x),f_2(x),f_3(x)。样本属于 某个类别c的概率为
- 并且我们我们可以针对类别1 求出 残差y_{11}(x)=0−p_1(x);类别2 求出残差y_{22}(x)=1−p_2(x);类别3 求出残差y_{33}(x)=0−p_3(x).
注意
- 决策树中的非叶子结点上是没有参数需要学习的,整个决策树需要学习的是叶子结点上的权重值.
- 决策树的复杂度可以用决策树的结点个数,树的深度,树叶权重的L2范数等来描述.
GBDT通过什么方式减少误差?
A:每棵树都是在拟合当前模型的预测值和真实值之间的误差,GBDT是通过不断迭代来使得误差见小的过程。
GBDT的效果相比于传统的LR,SVM效果为什么好一些
A:GBDT基于树模型,继承了树模型的优点 [对异常点鲁棒、不相关的特征干扰性低(LR需要加正则)、可以很好地处理缺失值、受噪音的干扰小]
如果有不相关的 feature,没什么干扰,如果数据中有不相关的 feature,顶多这个 feature 不出现在树的节点里。逻辑回归和 SVM 没有这样的天然特性(但是有相应的补救措施,比如逻辑回归里的 L1 正则化)。
Decision Tree 可以很好的处理 missing feature,这是他的天然特性,因为决策树的每个节点只依赖一个 feature,如果某个 feature 不存在,这颗树依然可以拿来做决策,只是少一些路径。像逻辑回归,SVM 就没这个好处。
Decision Tree 可以很好的处理各种类型的 feature,也是天然特性,很好理解,同样逻辑回归和 SVM 没这样的天然特性。
对特征空间的 outlier 有鲁棒性,因为每个节点都是 x < 𝑇 的形式,至于大多少,小多少没有区别,outlier 不会有什么大的影响,同样逻辑回归和 SVM 没有这样的天然特性。
数据规模影响不大,因为我们对弱分类器的要求不高,作为弱分类器的决策树的深 度一般设的比较小,即使是大数据量,也可以方便处理。像 SVM 这种数据规模大的时候训练会比较麻烦。
当然 Decision Tree 也不是毫无缺陷,通常在给定的不带噪音的问题上,他能达到的最佳分类效果还是不如 SVM,逻辑回归之类的。但是,我们实际面对的问题中,往往有很大的噪音,使得 Decision Tree 这个弱势就不那么明显了。而且,GBDT 通过不断的叠加组合多个小的 Decision Tree,他在不带噪音的问题上也能达到很好的分类效果。换句话说,通过GBDT训练组合多个小的 Decision Tree 往往要比一次性训练一个很大的 Decision Tree 的效果好很多。因此不能把 GBDT 理解为一颗大的决策树,几颗小树经过叠加后就不再是颗大树了,它比一颗大树更强。
GBDT 如何加速训练
A:小数据集使用True,可以加快训练。是否预排序,预排序可以加速查找最佳分裂点(不确定).在样本规模上的并行计算。
GBDT的参数有哪些?
A:分为三类
第一类Miscellaneous Parameters: Other parameters for overall functioning. 没啥用
其实主要是前两种参数。
第二类:Boosting Parameters: These affect the boosting operation in the model.
n_estimators 最大弱学习器的个数,太小欠拟合,太大过拟合
learning_rate 学习率,太大过拟合,一般很小0.1,和n_estimators一起调
subsample 子采样,防止过拟合,太小欠拟合。GBDT中是不放回采样
第三类:Tree-Specific Parameters: These affect each individual tree in the model.
max_features 最大特征数
max_depth 最大树深,太大过拟合
min_samples_split 内部节点再划分所需最小样本数,越大越防过拟合
min_weight_fraction_leaf 叶子节点最小的样本权重和。如果存在较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。越大越防过拟合
max_leaf_nodes:最大叶子节点数 ,太大过拟合
min_impurity_split:节点划分最小不纯度
presort:是否对数据进行预分类,以加快拟合中最佳分裂点的发现。默认False,适用于大数据集。小数据集使用True,可以加快训练。是否预排序,预排序可以加速查找最佳分裂点,对于稀疏数据不管用,Bool,auto:非稀疏数据则预排序,若稀疏数据则不预排序
GBDT如何调参?
A:以下便是整个寻优的过程,接下来把整个过程整理一下:
1、首先使用默认的参数,进行数据拟合;
2、从步长(learning rate)和迭代次数(n_estimators)入手;一般来说,开始选择一个较小的步长来网格搜索最好的迭代次数。这里,可以将步长初始值设置为0.1。对于迭代次数进行网格搜索;
3、接下来对决策树的参数进行寻优
4、首先我们对决策树最大深度max_depth和内部节点再划分所需最小样本数min_samples_split进行网格搜索。【min_samples_split暂时不能一起定下来,因为这个还和决策树其他的参数存在关联】
5、接着再对内部节点再划分所需最小样本数min_samples_split和叶子节点最少样本数min_samples_leaf一起调参;做到这里,min_samples_split要做两次网格寻优,一次是树的最大深度max_depth,一次是叶子节点最少样本数min_samples_leaf。
【具体观察min_samples_split的值是否落在边界上,如果是可以进一步寻优】
6、继续对最大特征数max_features进行网格搜索。做完这一步可以看看寻找出的最优参数组合给出的分类器的效果。
7、可以进一步考虑对子采样的比例进行网格搜索,得到subsample的寻优参数
8、回归到第2步调整设定的步长(learning rate)和迭代次数(n_estimators),注意两者的乘积保持不变,这里可以分析得到:通过减小步长可以提高泛化能力,但是步长设定过小,也会导致拟合效果反而变差,也就是说,步长不能设置的过小。