DenseNet
DenseNet模型的基本思路与ResNet一致,但是它建立的是前面所有层与后面层的密集连接(dense connection),它的名称也是由此而来。DenseNet的另一大特色是通过特征在channel上的连接来实现特征重用(feature reuse)。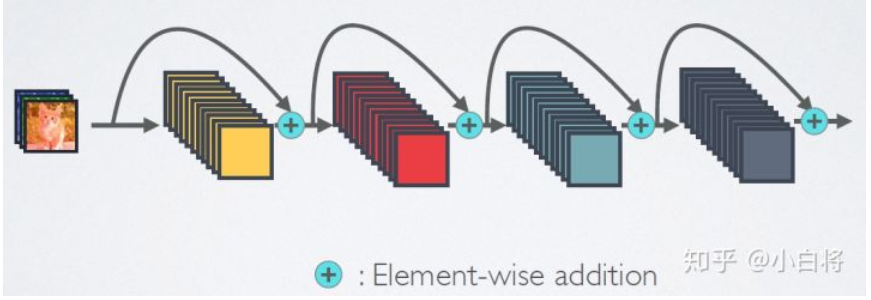
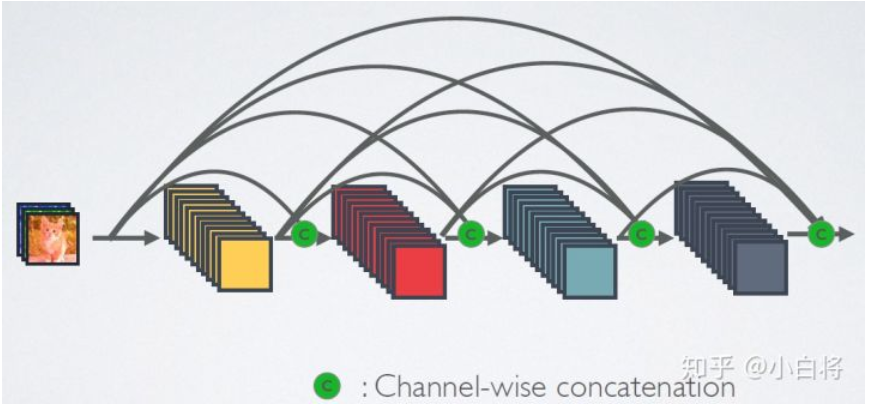
可以看到,ResNet是每个层与前面的某层(一般是2~3层)短路连接在一起,连接方式是通过元素级相加。而在DenseNet中,每个层都会与前面所有层在channel维度上连接(concat)在一起(这里各个层的特征图大小是相同的,后面会有说明),并作为下一层的输入。对于一个 L 层的网络,DenseNet共包含 $\frac{L(L+1)}{2}$ 个连接,相比ResNet,这是一种密集连接。而且DenseNet是直接concat来自不同层的特征图,这可以实现特征重用,提升效率,这一特点是DenseNet与ResNet最主要的区别。
如果用公式表示的话,传统的网络在 l 层的输出为:
而对于ResNet,增加了来自上一层输入的identity函数:
在DenseNet中,会连接前面所有层作为输入:
其中,上面的 $H_l(\cdot)$ 代表是非线性转化函数(non-liear transformation),它是一个组合操作,其可能包括一系列的BN(Batch Normalization),ReLU,Pooling及Conv操作。注意这里 l 层与 l-1 层之间可能实际上包含多个卷积层。
CNN网络一般要经过Pooling或者stride>1的Conv来降低特征图的大小,而DenseNet的密集连接方式需要特征图大小保持一致。为了解决这个问题,DenseNet网络中使用DenseBlock+Transition的结构,其中DenseBlock是包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式。而Transition模块是连接两个相邻的DenseBlock,并且通过Pooling使特征图大小降低。下图给出了DenseNet的网路结构,它共包含4个DenseBlock,各个DenseBlock之间通过Transition连接在一起。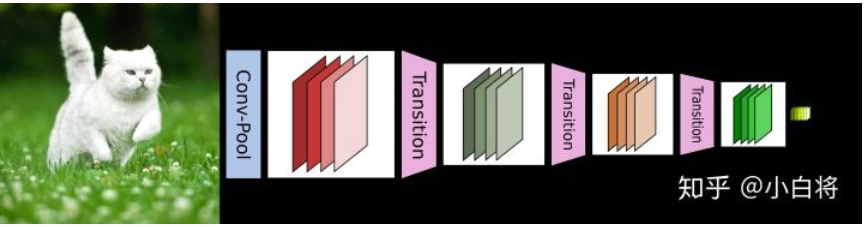
网络结构
DenseNet的网络结构主要由DenseBlock和Transition组成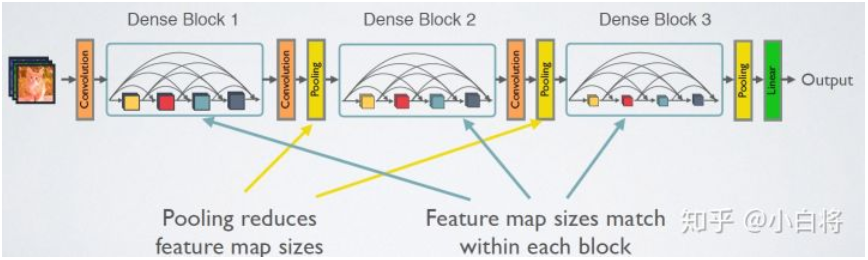
在DenseBlock中,各个层的特征图大小一致,可以在channel维度上连接。DenseBlock中的非线性组合函数 $H(\cdot)$ 采用的是BN+ReLU+3x3 Conv的结构,如下图所示。另外值得注意的一点是,与ResNet不同,所有DenseBlock中各个层卷积之后均输出 k 个特征图,即得到的特征图的channel数为 k ,或者说采用 k 个卷积核。 k 在DenseNet称为growth rate,这是一个超参数。一般情况下使用较小的 k (比如12),就可以得到较佳的性能。假定输入层的特征图的channel数为 k_0 ,那么 l 层输入的channel数为 k_0+k(l-1) ,因此随着层数增加,尽管 k 设定得较小,DenseBlock的输入会非常多,不过这是由于特征重用所造成的,每个层仅有 k 个特征是自己独有的。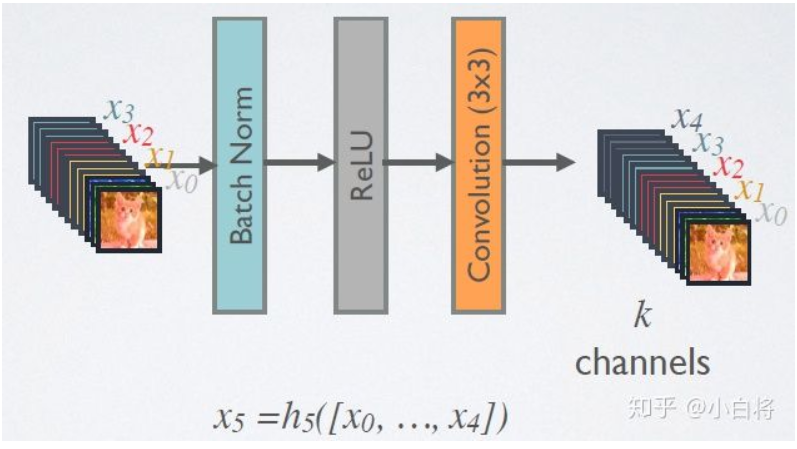
由于后面层的输入会非常大,DenseBlock内部可以采用bottleneck层来减少计算量,主要是原有的结构中增加1x1 Conv,如下图所示,即BN+ReLU+1x1 Conv+BN+ReLU+3x3 Conv,称为DenseNet-B结构。其中1x1 Conv得到 4k 个特征图它起到的作用是降低特征数量,从而提升计算效率。
对于Transition层,它主要是连接两个相邻的DenseBlock,并且降低特征图大小。Transition层包括一个1x1的卷积和2x2的AvgPooling,结构为BN+ReLU+1x1 Conv+2x2 AvgPooling。另外,Transition层可以起到压缩模型的作用。假定Transition的上接DenseBlock得到的特征图channels数为 m ,Transition层可以产生 $\lfloor\theta m\rfloor$ 个特征(通过卷积层),其中 $\theta \in$ (0,1] 是压缩系数(compression rate)。当 $\theta$=1 时,特征个数经过Transition层没有变化,即无压缩,而当压缩系数小于1时,这种结构称为DenseNet-C,文中使用 $\theta$=0.5 。对于使用bottleneck层的DenseBlock结构和压缩系数小于1的Transition组合结构称为DenseNet-BC。
DenseNet共在三个图像分类数据集(CIFAR,SVHN和ImageNet)上进行测试。对于前两个数据集,其输入图片大小为 32$\times$ 32 ,所使用的DenseNet在进入第一个DenseBlock之前,首先进行进行一次3x3卷积(stride=1),卷积核数为16(对于DenseNet-BC为 2k )。DenseNet共包含三个DenseBlock,各个模块的特征图大小分别为 32$\times$ 32 , 16$\times$ 16 和 8$\times$ 8 ,每个DenseBlock里面的层数相同。最后的DenseBlock之后是一个global AvgPooling层,然后送入一个softmax分类器。注意,在DenseNet中,所有的3x3卷积均采用padding=1的方式以保证特征图大小维持不变。对于基本的DenseNet,使用如下三种网络配置: \{L=40, k=12\} , \{L=100, k=12\} , \{L=40, k=24\} 。而对于DenseNet-BC结构,使用如下三种网络配置: \{L=100, k=12\} , \{L=250, k=24\} , \{L=190, k=40\} 。这里的 L 指的是网络总层数(网络深度),一般情况下,我们只把带有训练参数的层算入其中,而像Pooling这样的无参数层不纳入统计中,此外BN层尽管包含参数但是也不单独统计,而是可以计入它所附属的卷积层。 对于普通的 {L=40, k=12} 网络,除去第一个卷积层、2个Transition中卷积层以及最后的Linear层,共剩余36层,均分到三个DenseBlock可知每个DenseBlock包含12层。其它的网络配置同样可以算出各个DenseBlock所含层数。