Conv1d
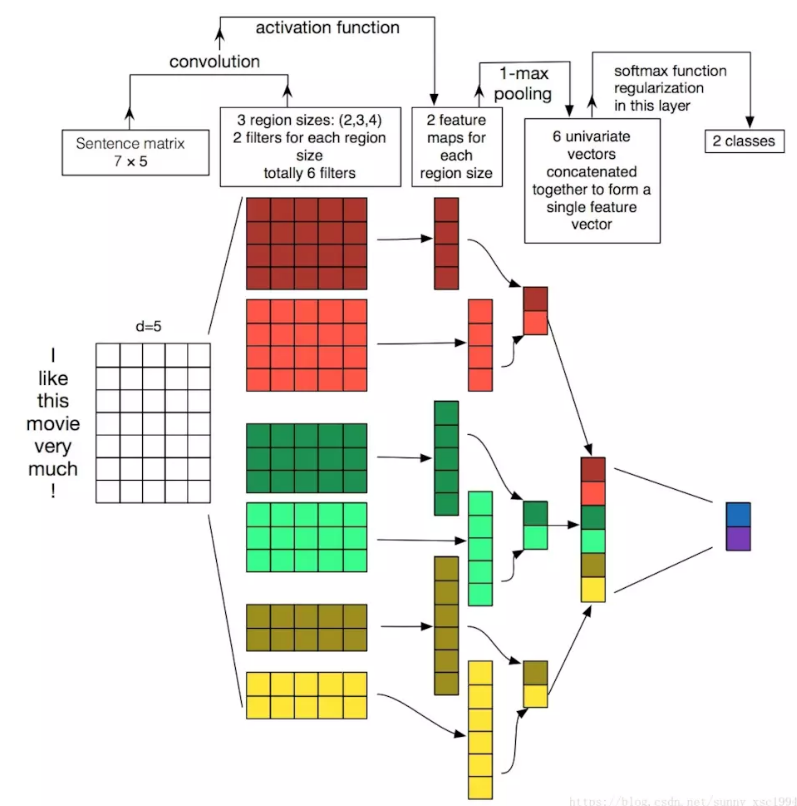
一维的卷积操作是一种比较常见的处理sequence和timeseries问题的方法,往往在后面跟上一个1维的池化层。卷积或者池化的维度就是timestep的维度,它可以学习到一些local pattern,这主要由其window大小而定。
相比于LSTM,这种计算要快很多。
常用的做法:
- 用Conv1d来处理简单的文本分类
- 把它和LSTM融合,利用Conv1D轻量级计算快的优点来得到低维度特征,然后再用LSTM进行学习。这对于处理long sequence 非常有用。
文献: - Convolutional Neural Networks for Sentence Classification
- A Convolutional Neural Networks for Modeling Sentences
- A Sensitivity Analysis of(and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification
LSTM hidden state
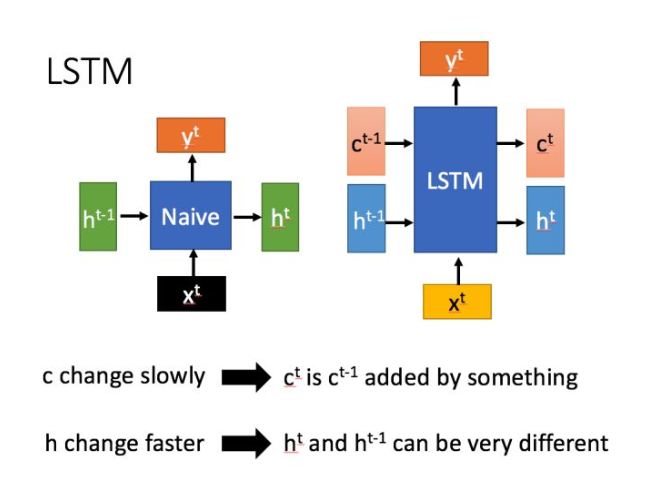
LSTM 与Naive RNN在结构上有明显的区别,新增的c可以对记忆的内容进行选择,遗忘不相关的记忆,记住相关记忆。
这里主要讨论一下 LSTM中的hidden state(事实上hidden_state和cell_state在LSTM中是以tuple形式存在的,并且两者的shape一样。(cell_state,hidden_state))
hidden state的维度为[num_layers*num_directions,batch_size,hidden_size]
这里hidden的维度里带着batch_size,这就导致,训练集和测试集的batch_size必须一致,否则与该参数不能匹配上。(这一点与CNN中不同)
解决办法:
如果是tf的话,可以采用tf.nn.dynamic_rnn的方式处理
或着自行进行数据的填充,将其填充为训练时batch_size大小的数据
torch.gather
在做项目的时候需要用到该函数
torch.gather(input, dim, index, out=None) → Tensor
沿给定轴 dim ,将输入索引张量 index 指定位置的值进行聚合.
对一个 3 维张量,输出可以定义为:1
2
3out[i][j][k] = input[index[i][j][k]][j][k] # if dim == 0
out[i][j][k] = input[i][index[i][j][k]][k] # if dim == 1
out[i][j][k] = input[i][j][index[i][j][k]] # if dim == 2
Parameter:
- input(Tensor)——源张量
- dim(int)——索引的轴
- index(LongTensor)——聚合元素的下标(index需要是torch.longTensor类型)
- Out(Tensor,optional)——目标张量
举例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21b = torch.Tensor([[1,2,3],[4,5,6]])
print b
index_1 = torch.LongTensor([[0,1],[2,0]])
index_2 = torch.LongTensor([[0,1,1],[0,0,0]])
print torch.gather(b, dim=1, index=index_1)
print torch.gather(b, dim=0, index=index_2)
-------结果
1 2 3
4 5 6
[torch.FloatTensor of size 2x3]
(b)
1 2
6 4
[torch.FloatTensor of size 2x2]
(b_{ij}=b[i,index[i,j]])
1 5 6
1 2 3
[torch.FloatTensor of size 2x3]
(b_{ij}=b[index[i,j],j])
Pytorch retain_graph
在Pytorch的使用中有时会需要用到retain_graph.retain_graph的作用是在由loss计算出一个一次梯度之后,中间变量参数不被立即释放掉,往往使用retain_graph是在存在两个loss的情况下.
而detach往往用在变量后面,用来标识某个变量不被计入计算图中,可以视为常量(不会对该变量之前的计算图产生任何影响).
CRF批处理
CRF在NER应用中如果不进行批处理的话,速度很慢,一条样本大概需要1.5秒.为了提升速度,需要并行计算,而批处理就是用来实现并行计算的方法
具体的细节可以看
详解条件随机场(CRF)-batch版本
#